Zweck des Tools
Vorgehensweise
Einstellmöglichkeiten
Interpretationshilfe
Darstellungsformen
Voraussetzungen
Werkzeuge
Beispiele
Begriffe
Formeln
Test auf Normalverteilung
-
Zweck des Tools
Der Test auf Normalverteilung dient dazu zu prüfen, ob die vorliegenden Daten ausreichend gut durch eine Normalverteilung beschrieben werden können. Viele statistische Methoden, wie zum Beispiel die Prozessfähigkeitsanalyse mit Cp und Cpk, setzen normalverteilte Daten voraus. Der Test liefert Hinweise darauf, ob diese Voraussetzung erfüllt ist und ob weitere Analysen auf dieser Basis durchgeführt werden können. Hierzu betrachtet man den p-Wert: Ist der p-Wert größer als 0,05, werden die Daten als annähernd normalverteilt behandelt.
Ein p-Wert > 0,05 bedeutet jedoch nicht, dass die Daten als „bewiesen normalverteilt“ gelten. Es zeigt lediglich, dass keine statistischen Hinweise auf eine Abweichung von der Normalverteilung vorliegen.
-
Beispiel Tomatensoße
Bei der Herstellung von Tomatensoße werden regelmäßig Viskositätswerte erfasst. Bevor weitere Analysen durchgeführt werden können, muss geprüft werden, ob die Messwerte annähernd normalverteilt sind.
Der p-Wert beträgt 0,111. Da dieser größer als 0,05 ist, liegen keine Hinweise auf eine Abweichung von der Normalverteilung vor. Die Daten können daher als annähernd normalverteilt behandelt werden.
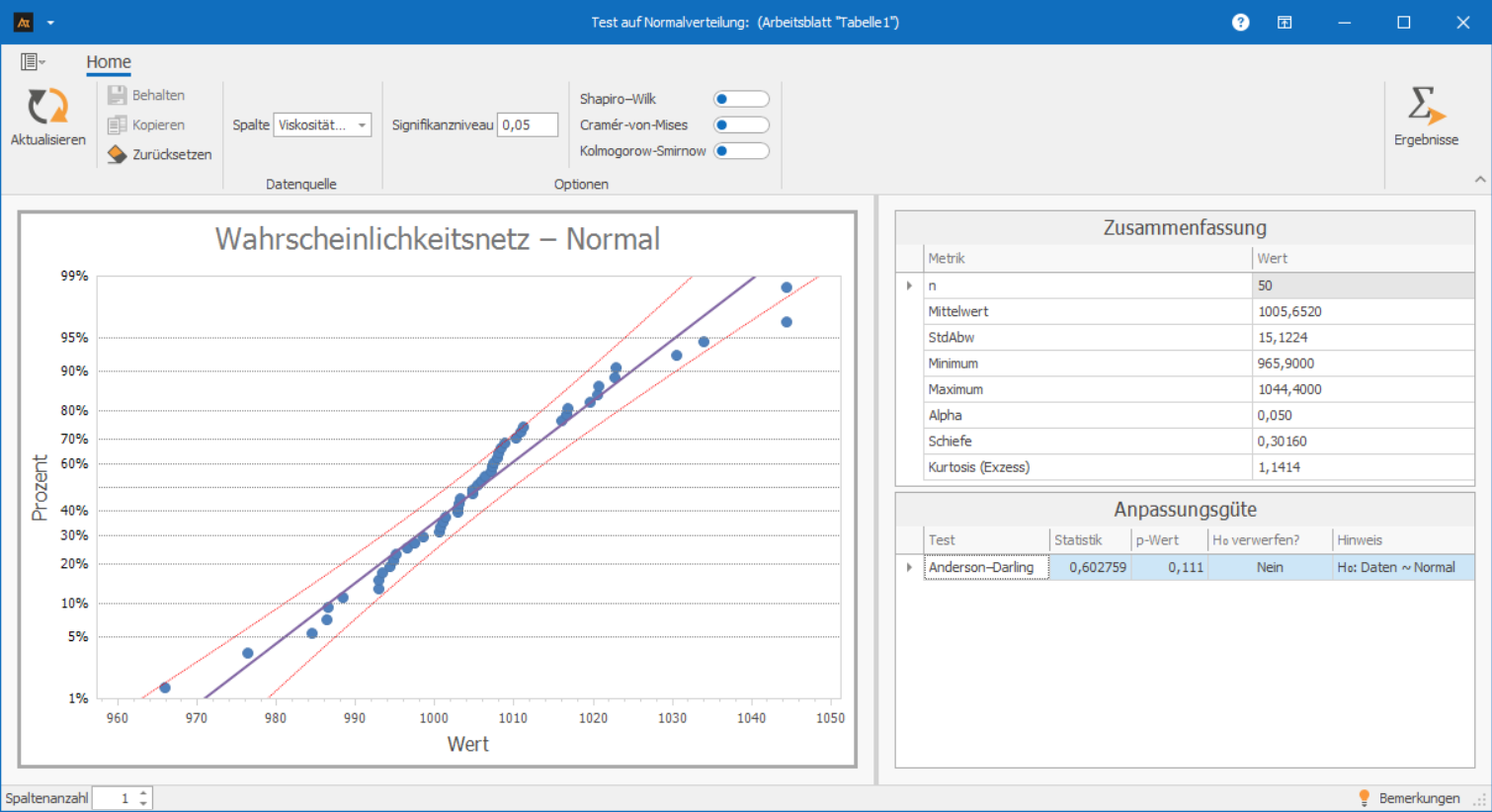
Wahrscheinlichkeitsnetz
Das Wahrscheinlichkeitsnetz ist eine grafische Hilfe, um zu prüfen, ob die Daten ungefähr wie eine Normalverteilung aussehen.
Dazu werden die Messwerte der Größe nach sortiert und mit den Werten verglichen, die man bei einer perfekten Normalverteilung erwarten würde.
- Liegen die Punkte nahe an der eingezeichneten Geraden, verhalten sich die Daten so, wie es eine Normalverteilung tun würde.
- Liegen die Punkte weit weg von der Geraden, oder bilden eine Kurve, deutet das darauf hin, dass die Daten nicht normalverteilt sind.
- Typische Muster wie S-Formen, starke Krümmungen oder Ausreißer zeigen, dass die Daten deutlich von der Normalverteilung abweichen.
Man kann sich die Gerade wie eine „Schablone“ vorstellen:
Je besser die Punkte darauf passen, desto eher sind die Daten normalverteilt.
Anderson
Neben dem Bild (Wahrscheinlichkeitsnetz) gibt es auch einen statistischen Test: den Anderson-Darling-Test.
Dieser überprüft rechnerisch, ob die Daten zu einer Normalverteilung passen.
Der Test gibt einen p-Wert aus:
- p-Wert größer als 0,05:
Es gibt keine Hinweise, dass die Daten von der Normalverteilung abweichen.
→ Die Daten können als annähernd normalverteilt betrachtet werden. - p-Wert kleiner oder gleich 0,05:
Der Test findet deutliche Abweichungen zur Normalverteilung.
→ Die Daten werden als nicht normalverteilt
Warum wird oft der Anderson-Darling-Test verwendet?
Er reagiert besonders empfindlich auf Abweichungen am Anfang und am Ende der Verteilung (also dort, wo Ausreißer sitzen). Dadurch erkennt er häufiger Auffälligkeiten als andere Tests und liefert in der Praxis zuverlässigere Ergebnisse.
-
Vorgehensweise
Vorarbeit
Eine stetige Messgröße auswählen und Messwerte erheben (z. B. Viskosität).
 Nutzung in AlphadiTab
Nutzung in AlphadiTab
- In der Measure-Phase das Tool Test auf Normalverteilung auswählen.
- Bei Spalte „Viskosität“ auswählen.
- Diagramm mit dem Button „Neu erstellen“ generieren.
Interpretation
Prüfen Sie anhand des p-Werts, ob die Daten als normalverteilt gelten können:
- p > 0,05 → Die Nullhypothese wird nicht verworfen. Es gibt keine Hinweise auf eine Abweichung von der Normalverteilung. Die Daten können als annähernd normalverteilt behandelt werden.
- p ≤ 0,05 → Die Nullhypothese wird verworfen. Die Daten gelten als nicht normalverteilt.
-
Voraussetzungen
Geeignetes Messmittel
Die Daten müssen mit einem zuverlässigen und für das Merkmal geeigneten Messmittel erhoben werden, um korrekte Ergebnisse sicherzustellen.
Warum ist das wichtig?
Ein ungeeignetes Messmittel kann den Eindruck erzeugen, dass die Daten nicht normalverteilt sind, obwohl es nur am Messmittel liegt.
-
Werkzeuge
(Wann sind andere besser geeignet?)
Bei nominalen oder ordinalen Daten ist ein Test auf Normalverteilung nicht sinnvoll, da diese Datentypen grundsätzlich nicht normalverteilt sein können. Eine Normalverteilung setzt stetige Messwerte voraus.
Diskrete Daten (z. B. Zähldaten) können in einigen Fällen zwar näherungsweise einer Normalverteilung folgen – insbesondere bei größeren Stichproben –, dennoch sollte immer geprüft werden, ob diese Annahme für die jeweilige Anwendung sinnvoll ist.
Wenn mehrere Verteilungen gleichzeitig geprüft werden sollen, ist das Tool „Verteilungstest“ besser geeignet. Dort stehen verschiedene stetige Verteilungen zur Auswahl, die automatisch miteinander verglichen werden können.
-
Beispiele
Produktion / Qualitätssicherung
Abfüllmenge Tomatensoße
In diesem Beispiel wurde die Abfüllmenge der Tomatensoße untersucht. Jede Füllung soll 500 ml enthalten. Bevor die Qualität des Abfüllprozesses bewertet werden kann, wird geprüft, ob die gemessenen Füllmengen wie eine typische Normalverteilung aussehen.
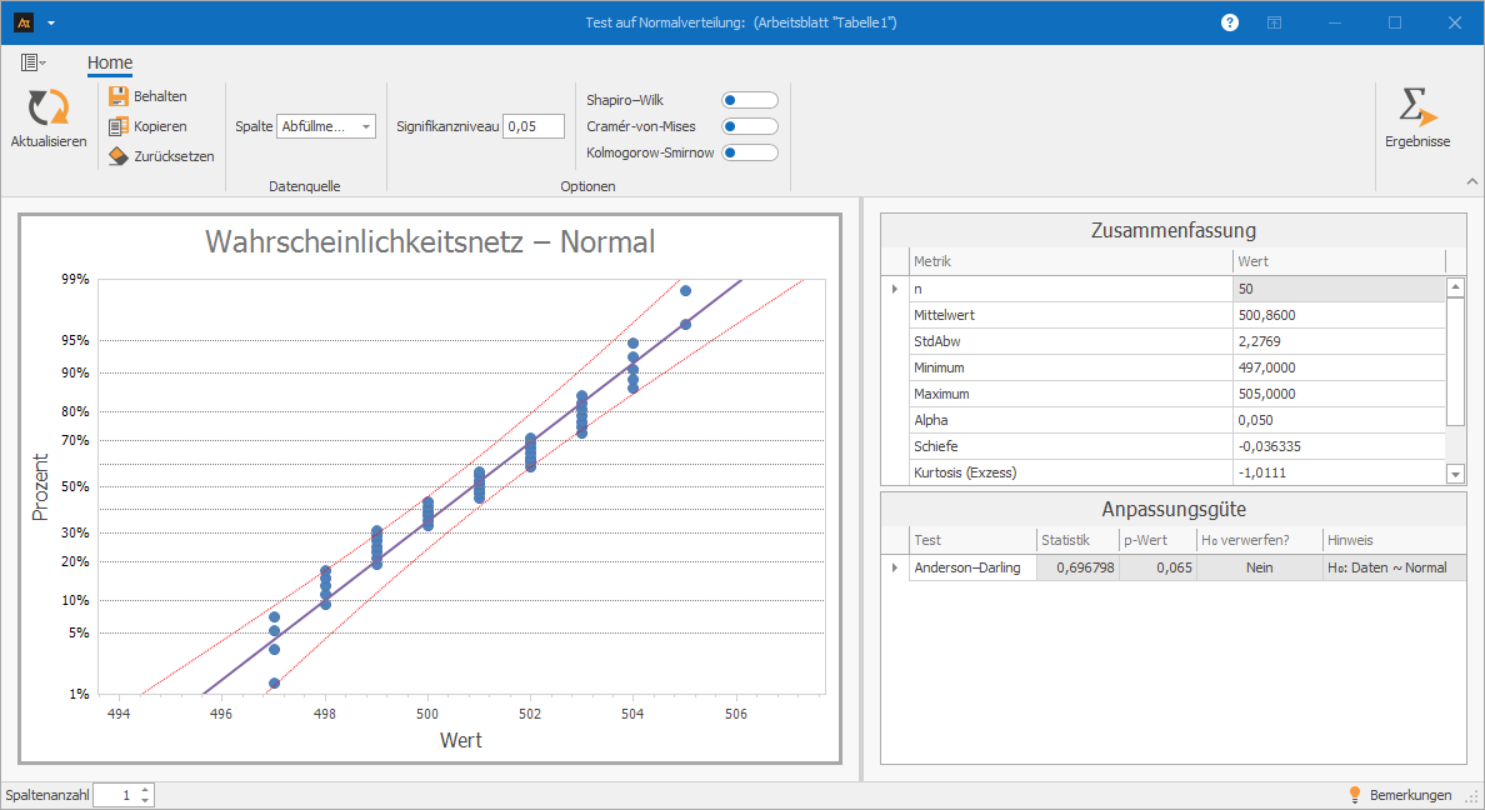
Interpretation:
Im Wahrscheinlichkeitsnetz liegen die Messpunkte überwiegend auf der eingezeichneten Geraden. Größere Abweichungen oder systematische Muster sind nicht zu erkennen.
Der Anderson-Darling-Test zeigt einen p-Wert von 0,065. Da der p-Wert größer als 0,05 ist, gibt es keine Hinweise auf eine signifikante Abweichung von der Normalverteilung. Die Daten können daher als annähernd normalverteilt behandelt werden.
Die sichtbaren Häufigkeitscluster können durch die Auflösung des Messmittels oder durch gerundete Werte entstehen. Sie stellen jedoch keine Auffälligkeit in Bezug auf die Verteilung dar. Insgesamt folgen die Daten der Normalverteilung ausreichend gut, sodass sie für die weitere Analyse als annähernd normalverteilt behandelt werden können.
Wareneingang/Logistik
Durchlaufzeit eines Auftrags
Im Wareneingang durchläuft jeder Auftrag einen Prüfschritt, bei dem Lieferscheine kontrolliert und Positionen im System erfasst werden. Während manche Vorgänge zügig bearbeitet werden, geraten andere ins Stocken: Ein fehlender Barcode, ein unvollständiger Lieferschein oder eine kurze Rückfrage führen dazu, dass einzelne Aufträge länger liegen bleiben. Dadurch entstehen sehr unterschiedliche Bearbeitungszeiten, die sich deutlich in den Messdaten widerspiegeln. Es soll überprüft werden, ob die Daten annähernd normalverteilt sind.
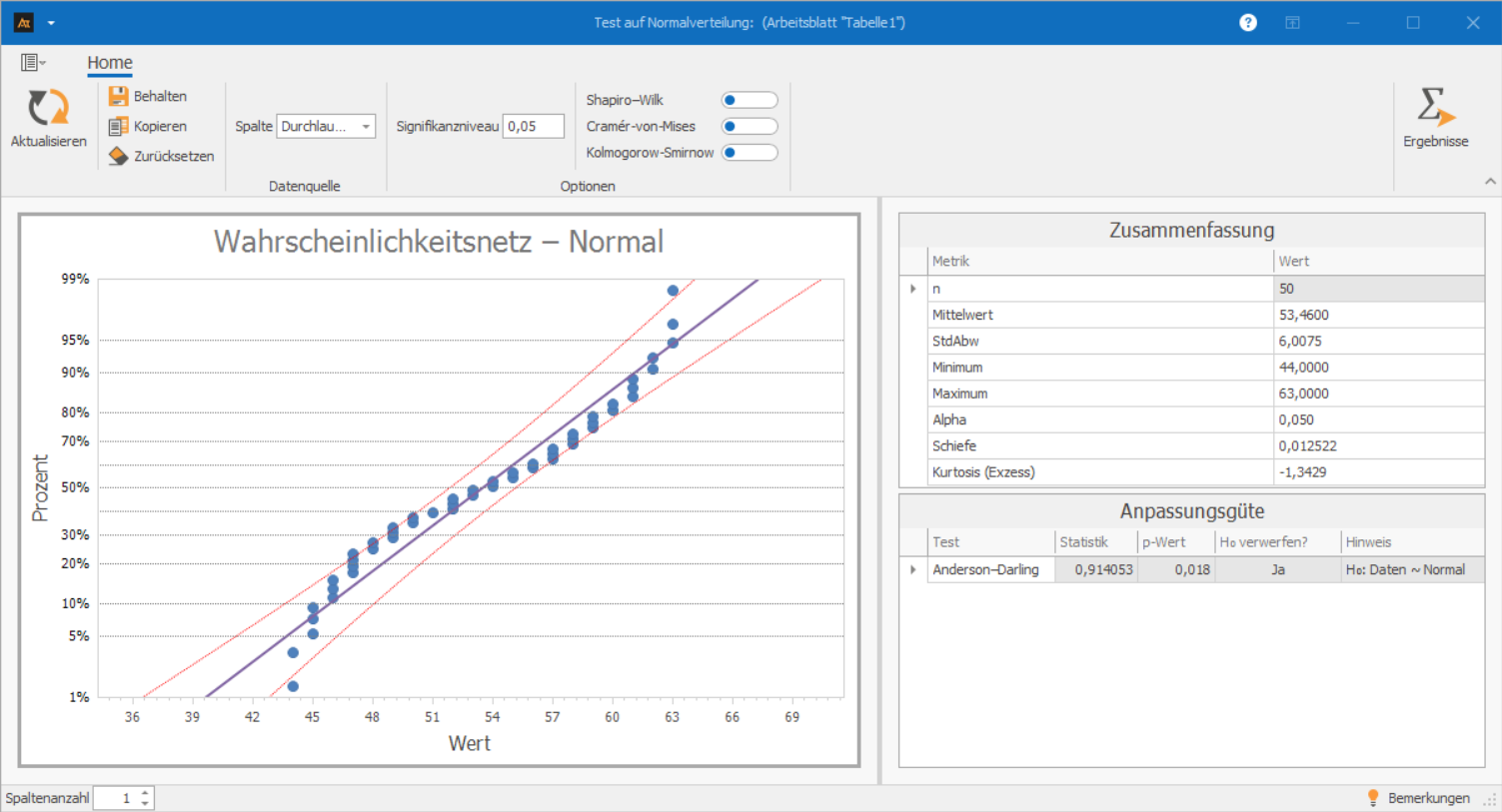
Interpretation:
Im Wahrscheinlichkeitsnetz weichen die Punkte deutlich von der Geraden ab. Besonders im unteren und mittleren Bereich ist erkennbar, dass die Daten nicht dem typischen Muster einer Normalverteilung folgen.
Der Anderson-Darling-Test bestätigt diese visuelle Einschätzung: Der p-Wert beträgt 0,018 und liegt damit unter 0,05. Die Nullhypothese der Normalverteilung wird somit verworfen: Die Daten sind nicht normalverteilt.
IT-Support
Reaktionszeit Anfragen
Im IT-Service-Desk gehen täglich viele unterschiedliche Anfragen ein. Manche Tickets können sofort beantwortet werden, weil die Lösung auf der Hand liegt oder nur ein kurzer Hinweis genügt. Andere Anfragen erfordern zunächst Rückfragen, eine Systemrecherche oder das Nachstellen eines Fehlers. Während einfache Fälle zügig bearbeitet werden, verzögert sich die Reaktion bei komplexeren Tickets deutlich. Dadurch entstehen sehr unterschiedliche Antwortzeiten – obwohl das Ziel besteht, dass die Antwortzeit 35 Minuten nicht überschreitet. Es soll überprüft werden, ob die Daten annähernd normalverteilt sind.
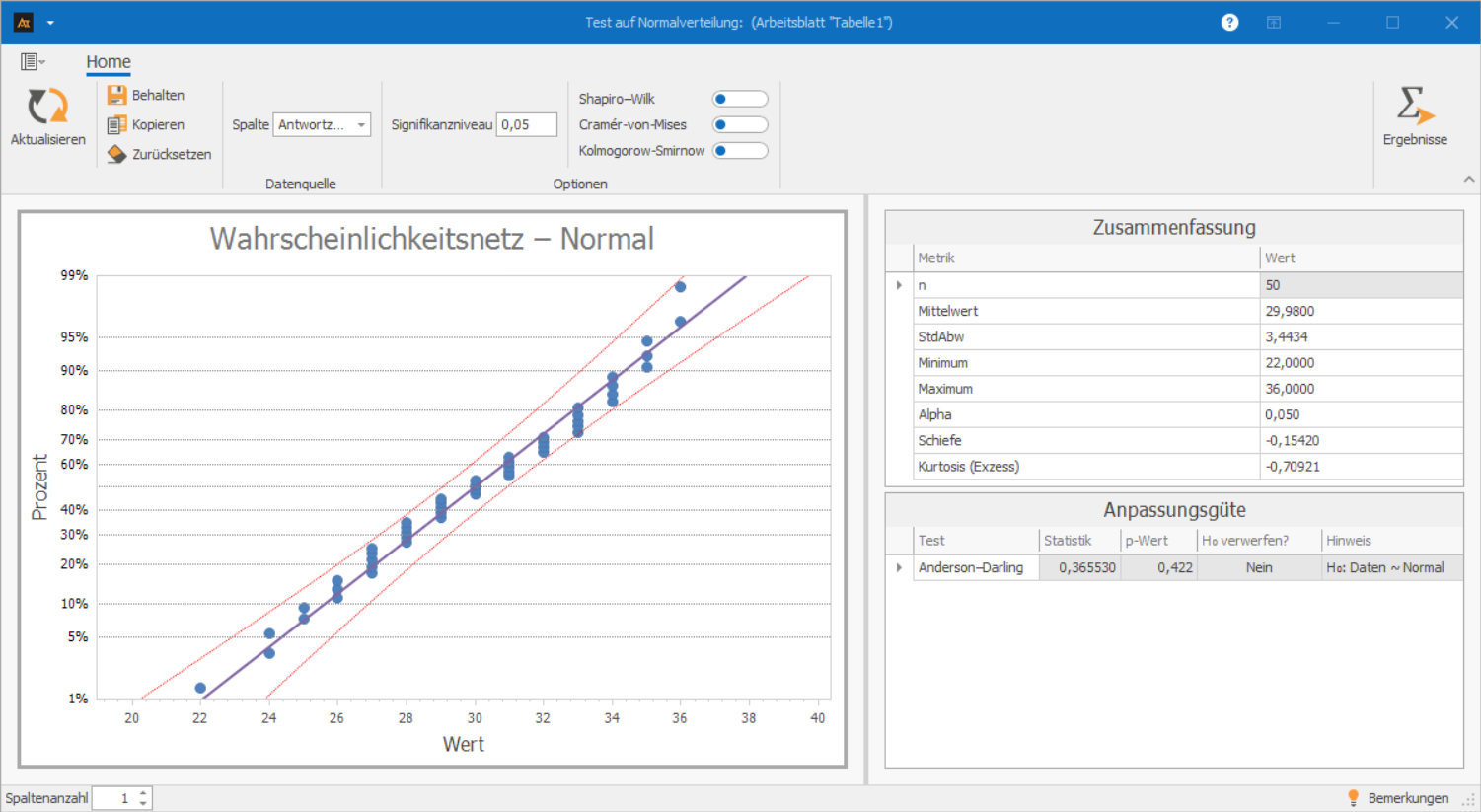
Interpretation:
Im Wahrscheinlichkeitsnetz liegen die Messpunkte überwiegend sehr nah an der roten Geraden. Es sind keine systematischen Abweichungen erkennbar, und das Punktmuster folgt dem erwarteten Verlauf einer Normalverteilung.
Der Anderson-Darling-Test bestätigt diesen Eindruck: Der p-Wert beträgt 0,422 und liegt damit deutlich über 0,05. Es gibt daher keine Hinweise auf eine signifikante Abweichung von der Normalverteilung.
Die Daten können als annähernd normalverteilt behandelt werden.
Development
Lebensdauer von Kugellagern
Für einen neuen Maschinentyp werden Kugellager im Dauerlauf getestet. Jedes Lager bleibt so lange im Prüfstand, bis es nicht mehr funktionsfähig ist. Auf diese Weise entstehen Lebensdauerdaten, die für die Bewertung der Bauteilzuverlässigkeit verwendet werden. Es soll überprüft werden, ob die Daten annähernd normalverteilt sind.
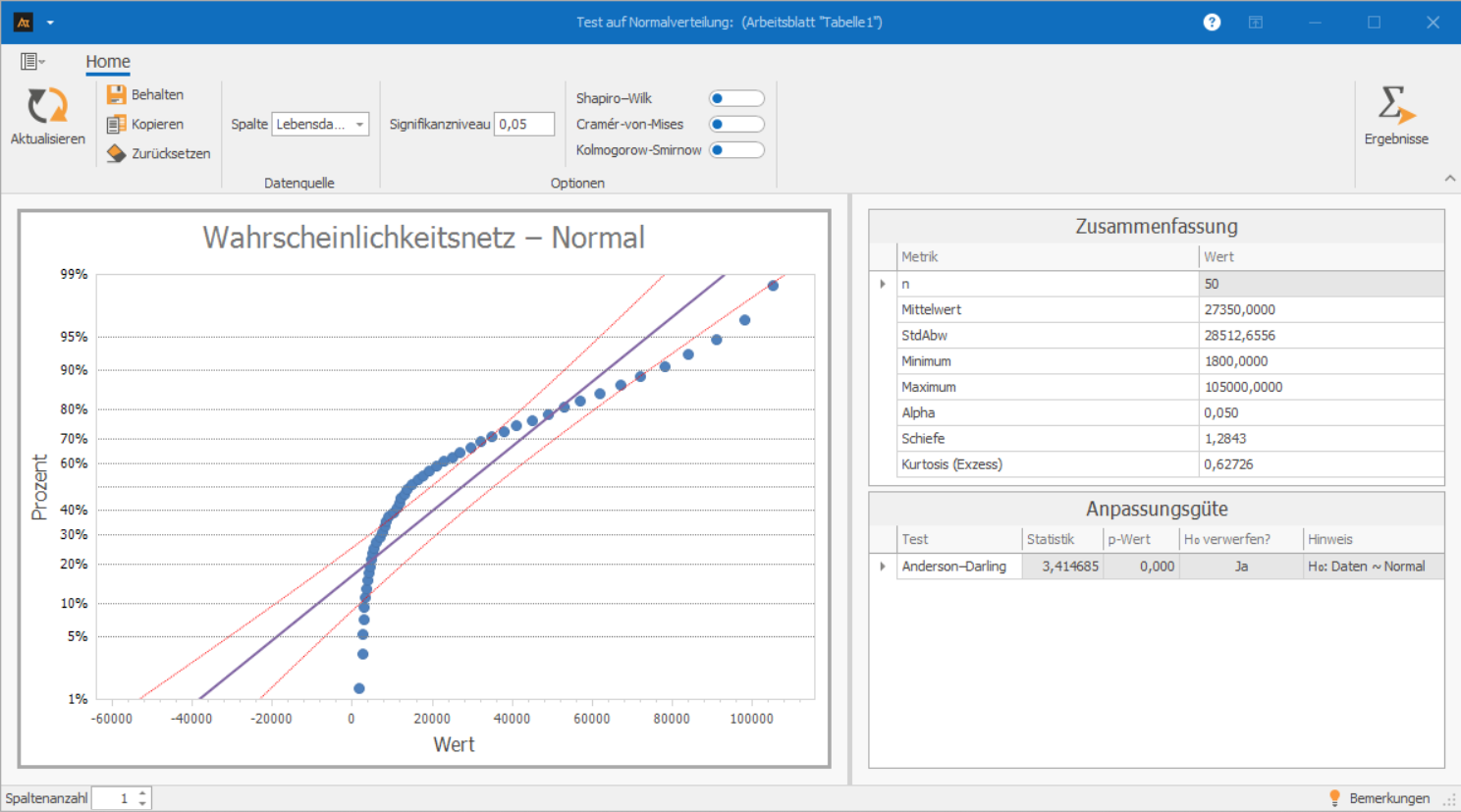
Im Wahrscheinlichkeitsnetz weichen die Messpunkte deutlich von der roten Geraden ab. Dies zeigt, dass die Verteilung der Lebensdauern nicht dem typischen Muster einer Normalverteilung entspricht.
Der Anderson-Darling-Test bestätigt diese visuelle Einschätzung:
Der p-Wert liegt bei 0,000. Damit liegt der p-Wert deutlich unter 0,05, sodass die Hypothese der Normalverteilung klar abgelehnt wird.
Die Daten sind nicht normalverteilt. Für die Analyse der Lebensdauer sollte daher eine verteilungsbasierte Auswertung (z. B. Weibull-Verteilung) verwendet werden.
-
Begriffe
Stetige Daten: Daten, die mit einem Messmittel erfasst werden und sowohl Einheiten als auch Nachkommastellen besitzen können.
Normalverteilung: Symmetrische, glockenförmige Verteilung
Anderson-Darling-Test: Statistischer Test zur Prüfung auf Normalverteilung.
p-Wert: Kennzahl zur Bewertung des Testergebnisses.
A²-Statistik: Maß für die Abweichung der Daten von der Normalverteilung
x̄ = Mittelwert der Stichprobe: Durchschnittswert der erhobenen Messdaten.
s = Standardabweichung der Stichprobe: Maß für die Streuung der Daten um den Mittelwert.
n = Stichprobenumfang: Anzahl der Messwerte in der Stichprobe
-
Formeln
Die Normalverteilungsprüfung basiert auf dem Anderson-Darling-Test, wie er im NMath-Paket umgesetzt ist.
Mittelwert
\( \bar{\mathrm{x}}=\frac{1}{\mathrm{n}}\sum_{i=1}^{\mathrm{n}}\mathrm{x}_i \)
Standardabweichung
\( \mathrm{s}=\sqrt{\frac{1}{\mathrm{n}-1}\sum_{i=1}^{\mathrm{n}}(\mathrm{x}_i-\bar{\mathrm{x}})^2} \)
Notation:
x̄ = Mittelwert der Stichprobe
s = Standardabweichung der Stichprobe
n = Stichprobenumfang
xi = ite Messwert
-
Schlagwörter
