Purpose of the tool
Procedure
Settings
Interpretation guide
Forms of representation
Requirements
Tools
Examples
Terms
Formulas
Histogram
-
Purpose of the tool
A histogram is a graphical tool used to display the frequency distribution of a continuous variable. It shows how measured values are distributed across classes (bins) and allows for an initial assessment of the shape of the distribution (e.g., symmetric, skewed, multimodal).
By displaying the frequencies, different data sets can be quickly compared with one another, for example, before and after a process improvement or between different machines, shifts, or material batches.
-
Example tomato sauce:
Viscosity measurements are routinely performed during the production of tomato sauce. To get an initial overview of the distribution, a histogram is created. This shows at a glance whether the data is symmetrical or skewed and whether there are any clusters or unusual outliers.
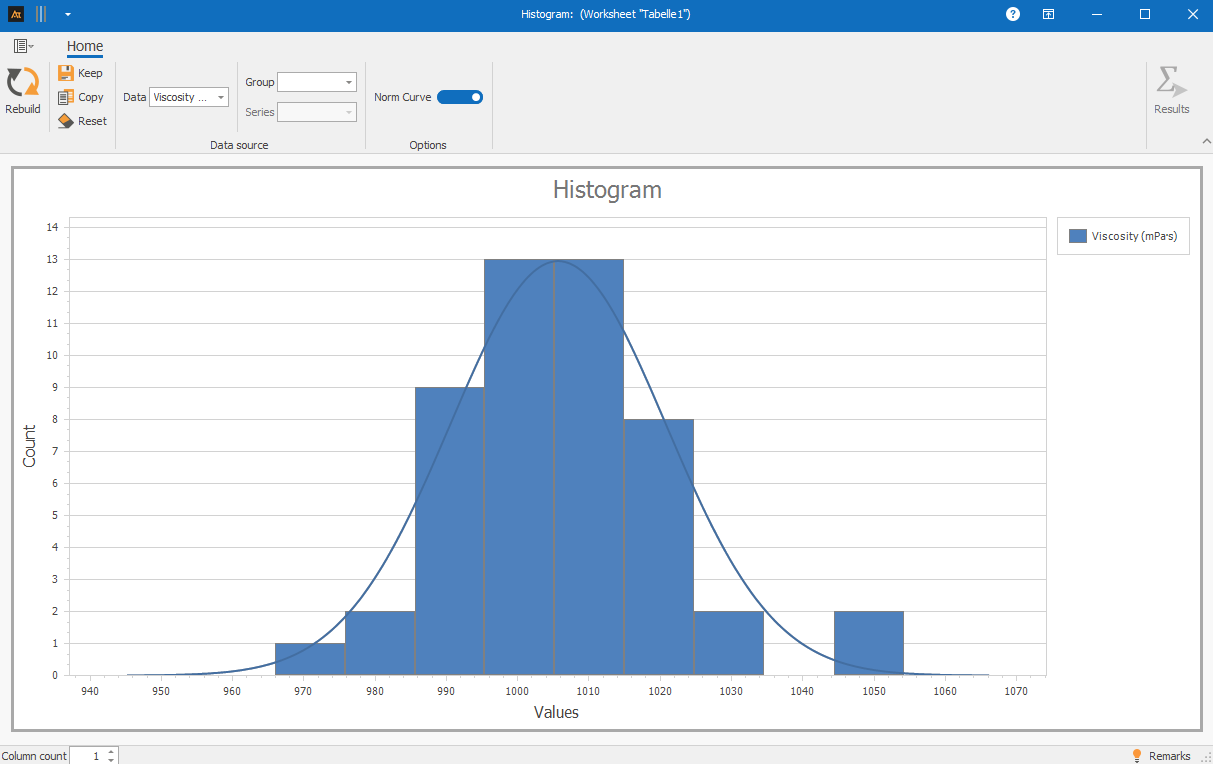
Explanations of the results:
A histogram consists of several elements that together describe the distribution of the data:
- Classes (bins): Intervals into which the measured values are divided.
- Bar height: Number (absolute frequency) or proportion (relative frequency) of values within a class.
- Class width: Width of the intervals (has a strong influence on the appearance).
- Distribution shape: Indications of symmetry, skewness, multimodality, and “long” tail regions.
-
Procedure
(How was this graphic created?)
Preliminary Work
- Select a continuous measurement parameter and collect measurement data (e.g., viscosity).
 Use in AlphadiTab
Use in AlphadiTab
- In the Measure phase, select the Histogram tool.
- Under “Data,” select “Viscosity.”
- Generate the chart using the “Create New” button.
Interpretation
- Is the distribution approximately symmetrical? → Indication of a “balanced” distribution.
- Is the distribution clearly skewed (to the right/left)? → Indication of an asymmetric process / mixtures / boundaries / disruptive influences.
- Are there multiple frequency peaks (multi-peaked)? → Indication of different causes/clusters (e.g., shifts, machines, material batches).
- Are there conspicuous edge classes with few values or gaps? → Check data (measurement resolution, rounding, special cases, process jumps).
- Are multiple histograms displayed? → Compare the location (typical range), dispersion (width of the distribution), and shape (skewness/multi-peakedness) between the groups.
-
Interpretation Guide
General Overview
- What is the shape of the distribution (symmetric / skewed / multimodal)?
- How wide is the distribution (large/small spread)?
- Are there any unusual clusters, gaps, or outliers?
- Is the choice of classes (number/width) plausible?
For known specifications
- Is the majority of the values within the specification range?
- Are there clusters near the upper/lower specification limits or beyond them?
For multiple histograms
- Do the distributions differ in location, range, or shape?
- Can differences be explained by class selection or a small sample size?
-
Forms of presentation
Various display options are available for the histogram. The chart’s appearance changes depending on whether one or more data series, as well as additional groups or series, are selected. Data can thus be visualized as individual bars, grouped, or broken down by series, and compared specifically with one another. All of the following display formats are based on the same file but differ in the selection of columns used. The procedure for each is described in the individual tiles.
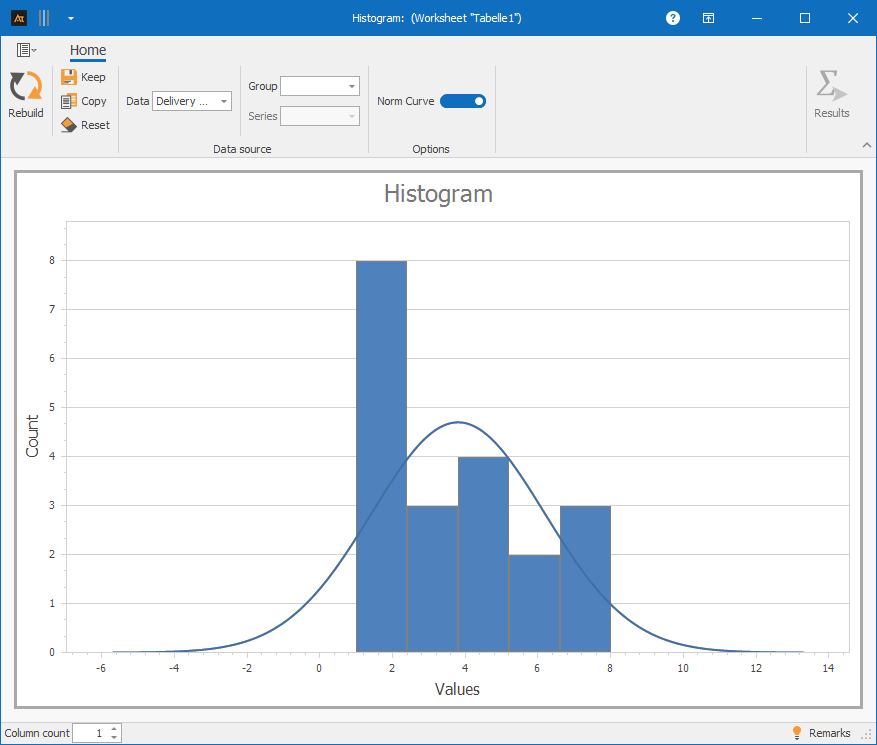
A data series: Column A
Procedure:
Step 1: For “Data,” select only column A
Step 2: For “Group,” select column D (Process Status)
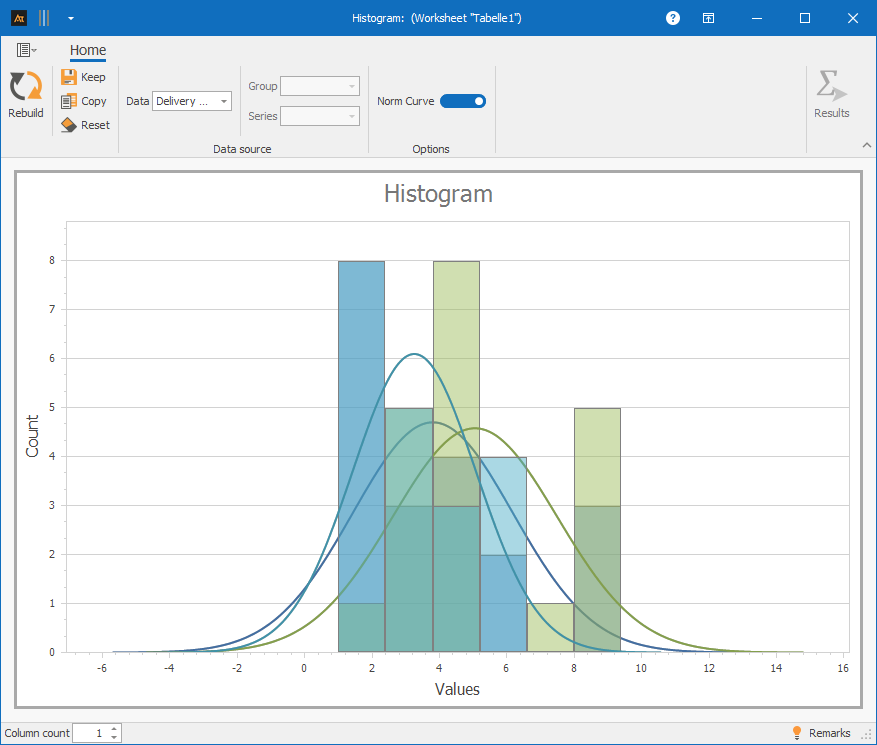
A data series and group: Column A and Column D
Procedure:
Step 1: Under “Data,” select only column A
Step 2: Under “Group,” select column D (Process Status)
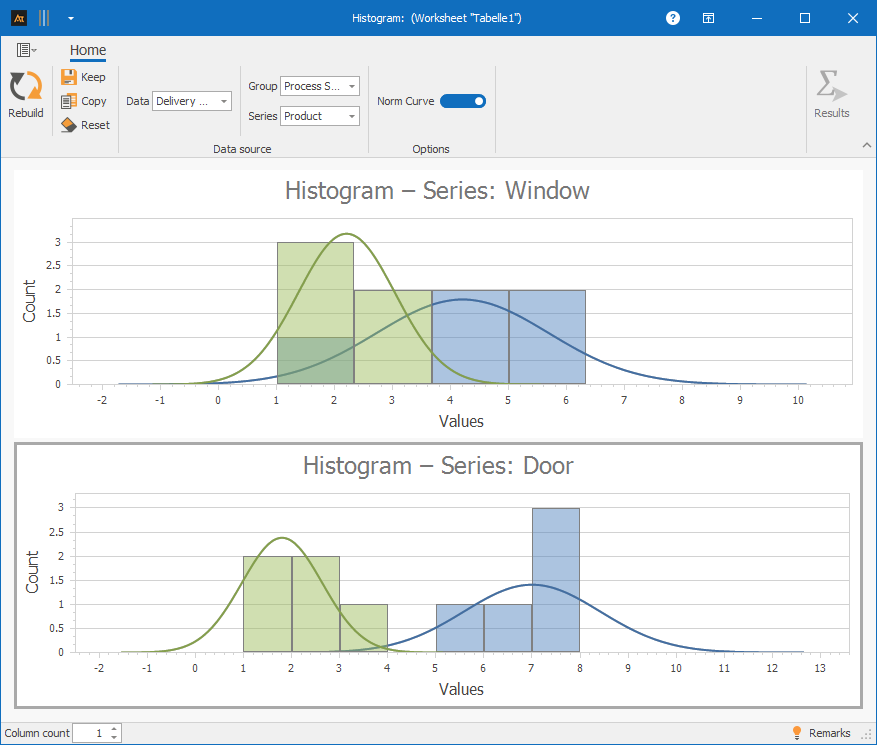
A dataset with group and series: Columns A, D, and E
Procedure:
Step 1: Under “Data,” select only column A
Step 2: Under “Group,” select column D (Process Status)
Step 3: Under “Series,” select column E (Product)
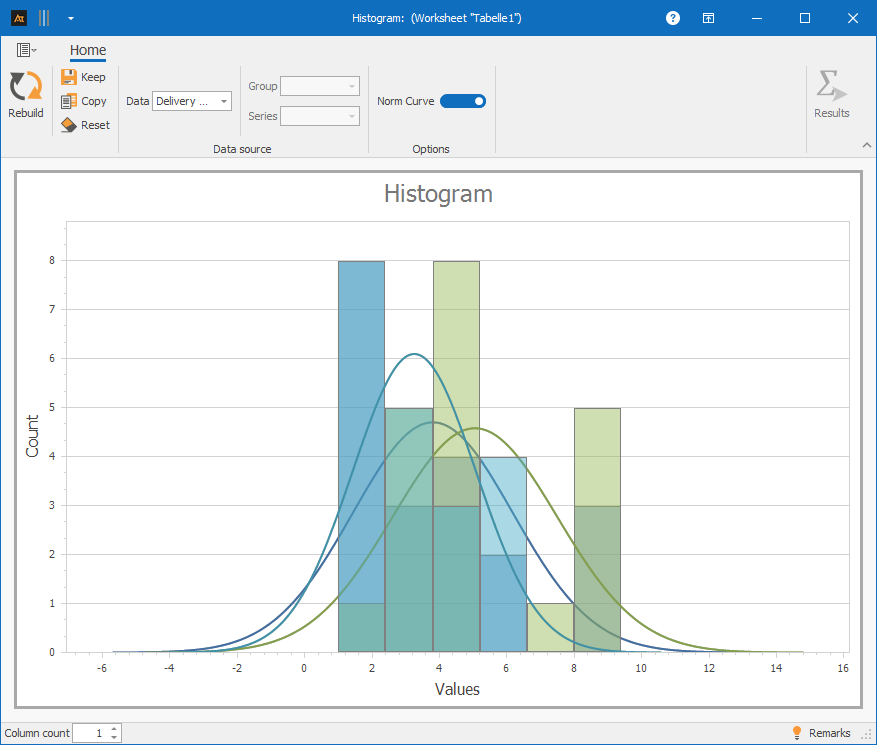
Multiple data sets: Columns A–C
Procedure:
Step 1: Select columns A–C in the data
-
Requirements
- At least quantitative data (countable or measurable data)
- A suitable measuring instrument, since outliers can often result from measurement errors.
-
Tools
(When are other options more suitable?)
- If the data is nominal or ordinal.
- If specific statements about normal distribution or process capability are required: Use a normality test or Cp/Cpk.
Development
Development of the old vs. new formula
A new formulation is currently being tested in the development phase. A histogram will be used to determine whether the viscosity distribution of the new formulation differs from that of the previous one, or whether both formulations exhibit similar distribution patterns.
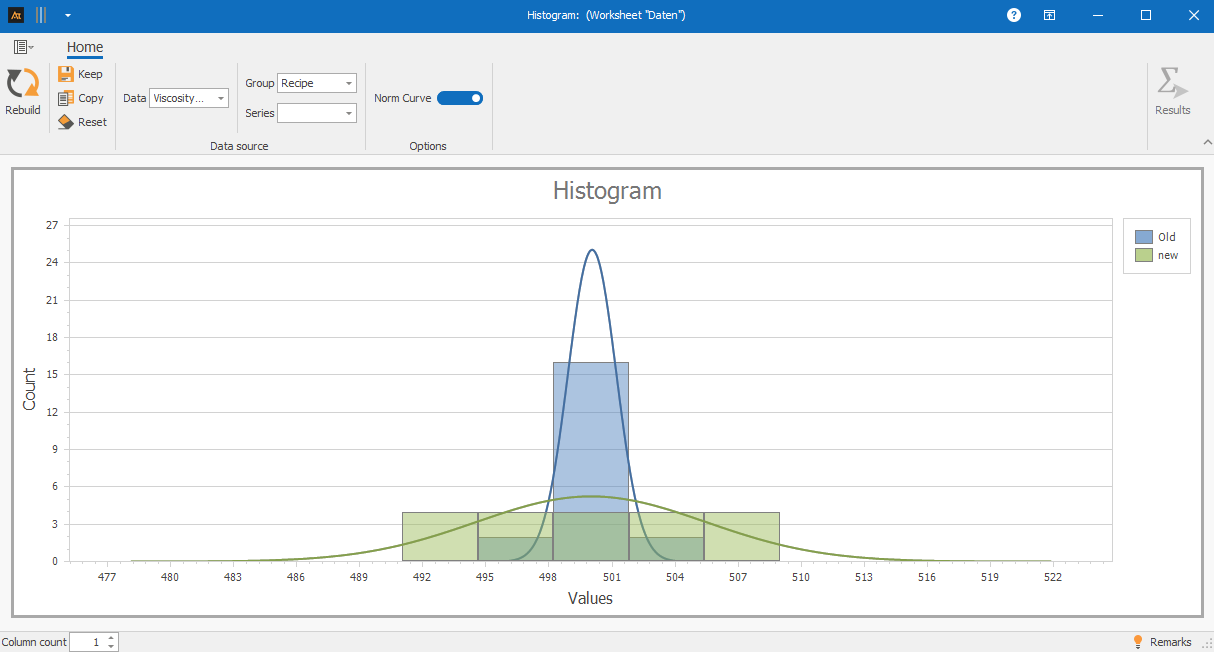
The histogram shows that the viscosity distributions of the old and new formulations largely overlap within the typical range of values. The main frequency ranges fall within similar classes, so no clear difference in the position of the distribution can be observed.
It is noticeable, however, that the distribution of the new formulation is broader. The frequencies are spread across more classes, indicating a greater dispersion of viscosity values.
Production/Quality Assurance
Order processing time
Quality assurance found that some viscosity values were outside the expected range. A histogram will be used to determine whether this pattern occurs across all production lines or whether individual lines differ.
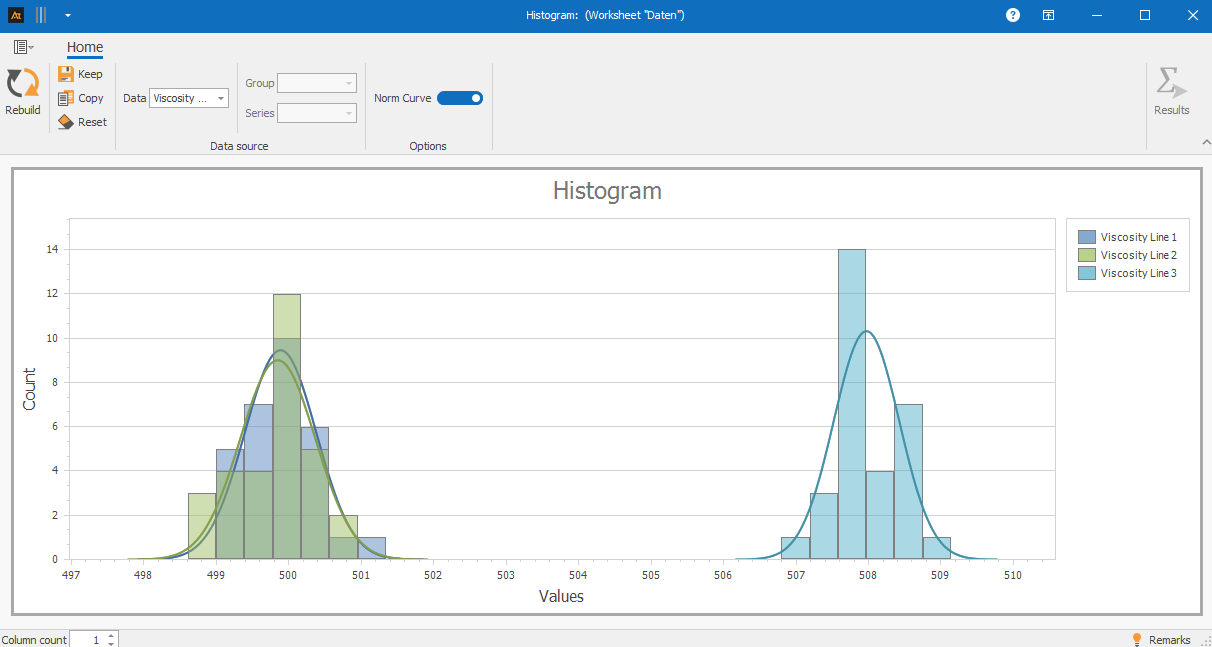
The histogram shows that production lines 1 and 2 have a similar distribution shape and a comparable typical range of viscosity values. The frequencies are concentrated in the same classes, which suggests similar process behavior.
The distribution for production line 3, on the other hand, is shifted, as the center of gravity of the frequencies lies in higher classes.
The dispersion is comparable across all three lines; however, individual outlier classes in line 3 show isolated values, which may indicate special process conditions or disruptive influences.
Service
Response Time for Inquiries
The IT service desk handles requests from multiple locations. Although standardized service processes are in place, the operating conditions may vary from one location to another. A histogram will be used to determine whether there are differences in the distribution of ticket turnaround times.
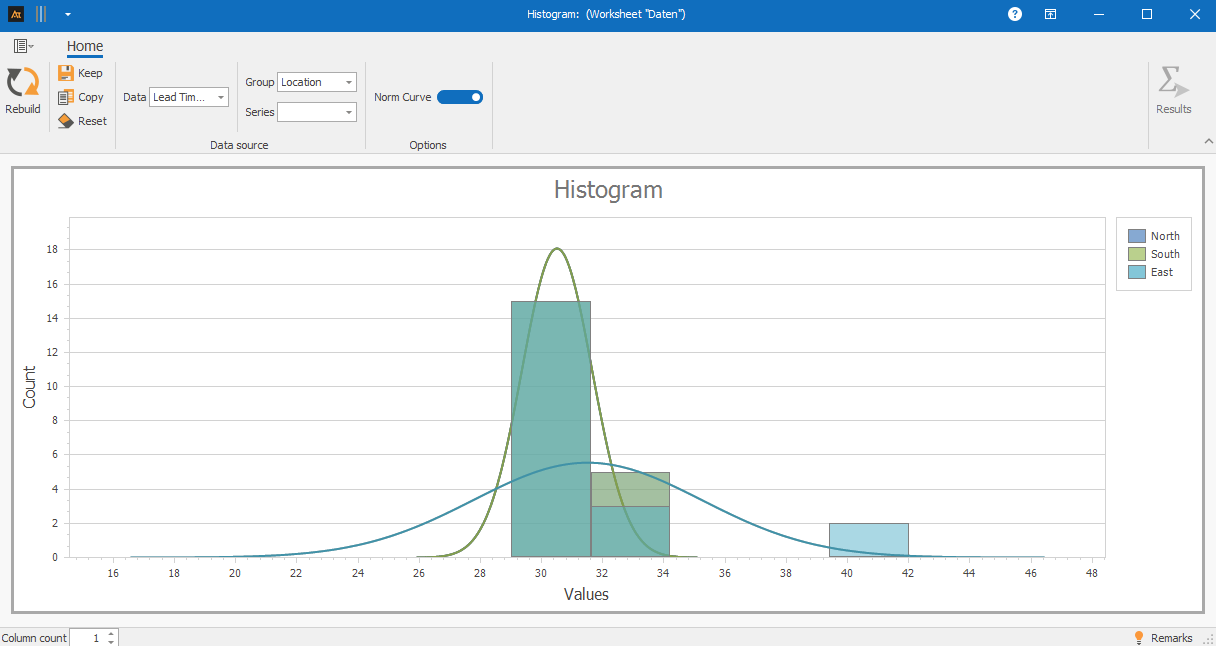
In the histogram, the main ranges of processing times at all locations fall within a similar range of values. This shows that typical turnaround times do not differ significantly between locations.
At the same time, one location shows an outlier group with very long processing times. These few values influence the distribution at the edge without significantly altering the typical processing range.
The histogram highlights these exceptional cases and shows that they represent isolated incidents rather than a general problem at the location.
Sales
Sales ratio by region
The sales department handles sales opportunities across multiple regions. Differences in market conditions and the intensity of competition can affect the sales conversion rate. A histogram will be used to determine whether the distributions differ across regions and products.
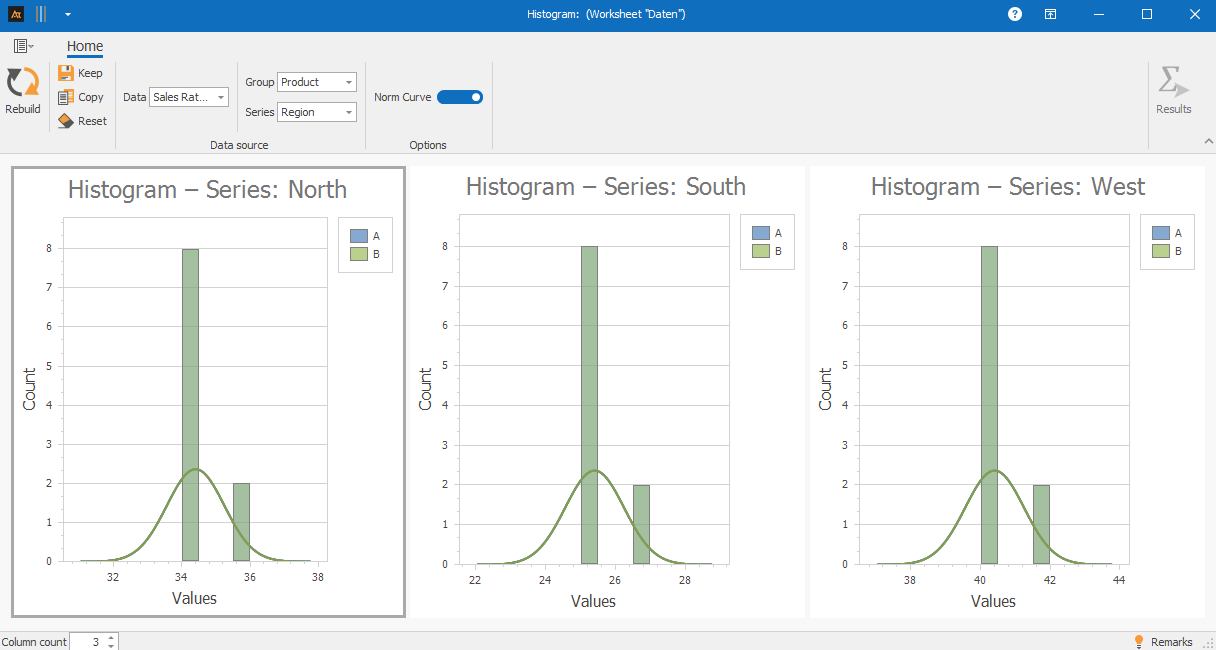
The histogram shows clear differences in the distribution of sales quotas across regions. In the West region, the frequencies are concentrated in higher classes, while in the South region, the values are more frequently found in lower classes.
The distributions of the two products are identical across all regions, so neither Category A (blue) nor Category B (green) can be distinguished on its own in the histogram. A better tool in this case is the box plot.
Logistics
Delivery time to the logistics center
In logistics, customer orders are processed across multiple distribution centers. Even though the processes are the same, delivery times can vary. A histogram will be used to analyze whether the distributions of delivery times differ between the distribution centers.
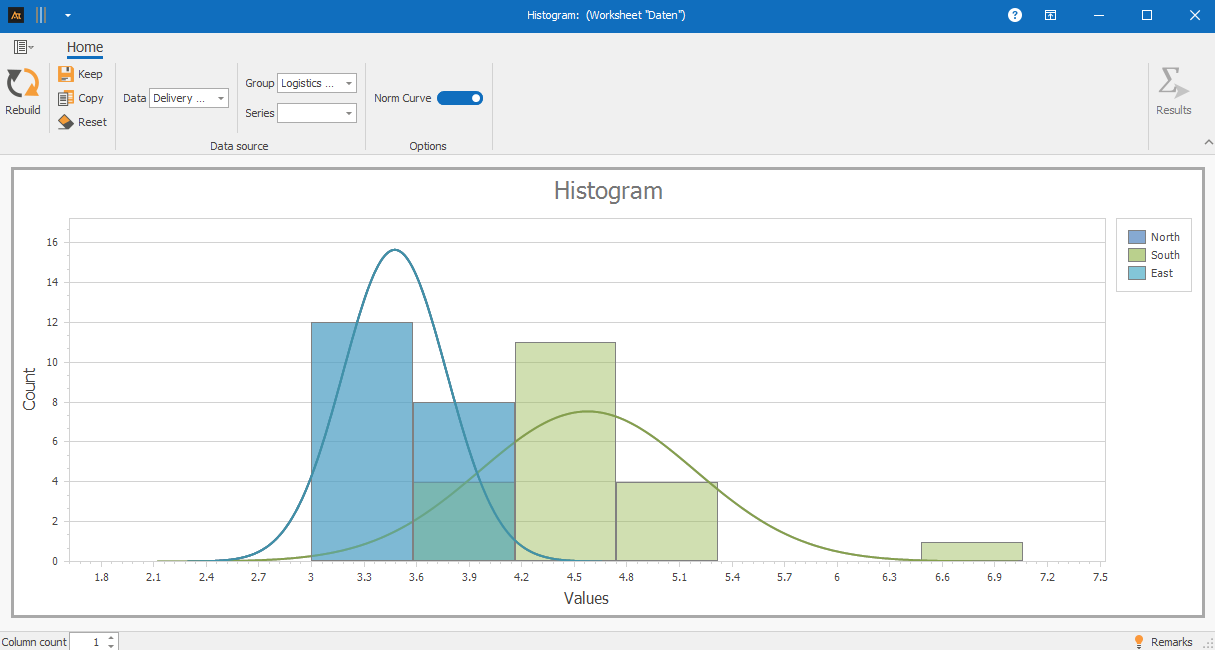
In the histogram, the typical delivery times for all logistics centers fall within a similar range. The frequencies are concentrated in comparable categories, suggesting similar standard processes.
However, for one logistics center, a cluster of longer delivery times is visible at the edges of the distribution. These few values indicate exceptional circumstances or isolated cases.
Purchasing
Supplier Comparison
In purchasing, materials are sourced from various suppliers. A histogram is used to determine whether there are differences in on-time delivery rates among suppliers. The on-time delivery rate is calculated as the percentage of deliveries that arrive on time.
On-time delivery rate [%] indicates how often deliveries are made on time. A delivery is considered on time if it arrives within the agreed delivery window. The on-time delivery rate is calculated as the percentage of on-time deliveries.
The on-time delivery rate is calculated for each week, e.g.:
( mathrm{On-time delivery rate}(%)=frac{mathrm{on-time},mathrm{deliveries}}{mathrm{total deliveries}}cdot100 )
For the histogram, the on-time delivery rate is calculated over several calendar weeks. Each data point corresponds to a supplier’s on-time delivery rate for a given week.
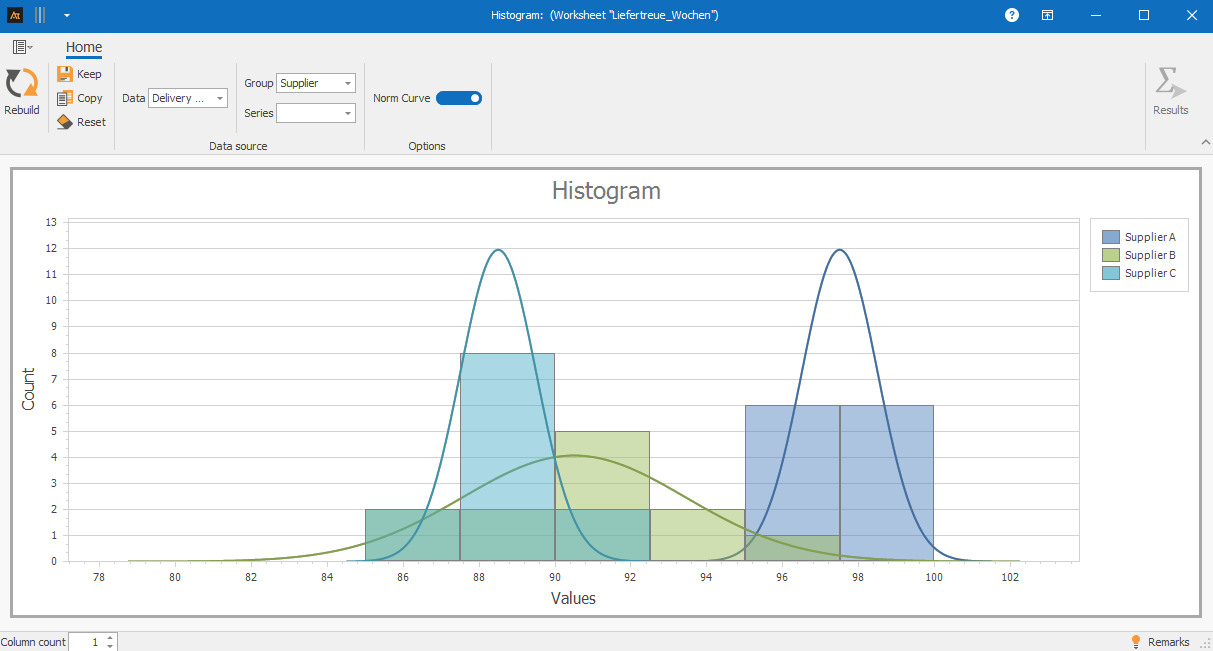
The histogram shows differences in the distribution of on-time delivery rates among the suppliers. Supplier A exhibits a strong concentration in the higher percentage categories, indicating a stable and high on-time delivery rate.
Supplier C also shows a relatively narrow distribution, but with a concentration in lower categories.
Supplier B’s distribution is significantly broader and includes a few very low values. This indicates more unstable performance with greater fluctuations.
The histogram thus shows that standard delivery times differ only slightly, while individual exceptions should be analyzed in detail.
Planning
Forecast deviation
In production planning, demand forecasts are created. A histogram is used to analyze how the distribution of forecast variances differs across various planning horizons.
The forecast variance is calculated by comparing the planned demand with the actual demand. To present the variance in a comparable way, it is expressed as a percentage.
The calculation is as follows:
( mathrm{Forecast deviation}(%)=frac{mathrm{planned},mathrm{demand}-mathrm{actual},mathrm{demand}}{mathrm{actual},mathrm{demand}}cdot100 )
- A positive value means that the demand was overestimated.
- A negative value means that demand was underestimated.
- A value close to 0% indicates a very accurate forecast.
By expressing the deviation as a percentage, forecast deviations can be compared independently of absolute quantities and clearly displayed in a histogram.
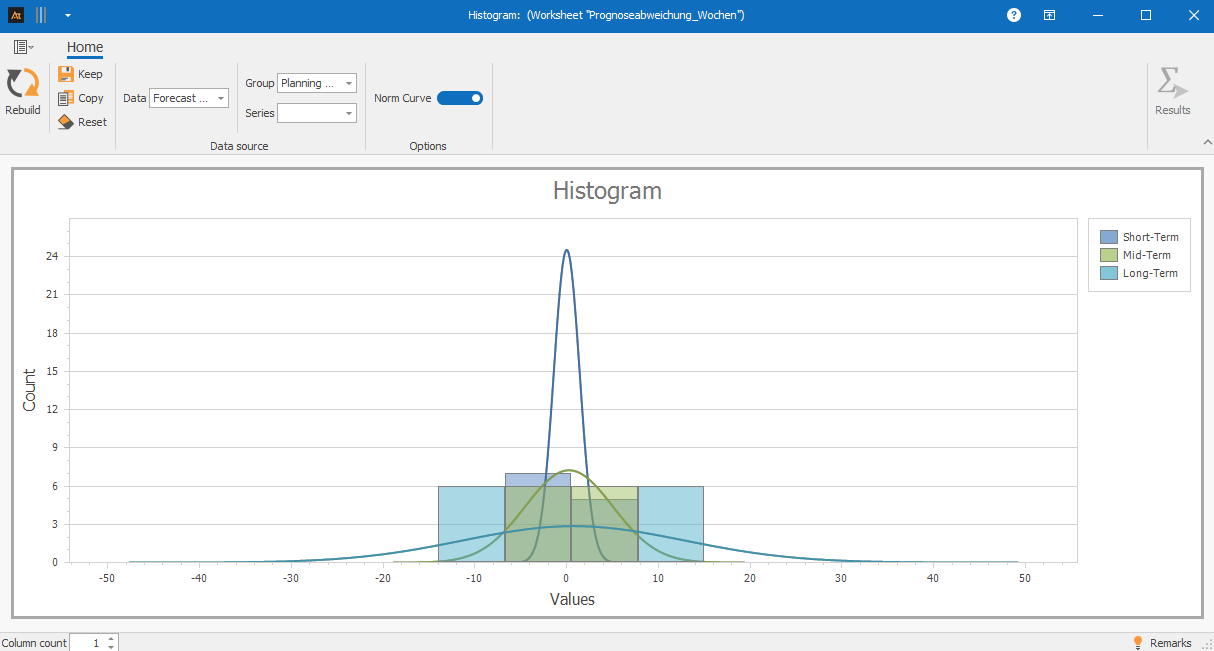
The histogram shows that short-term planning exhibits a narrow distribution of forecast deviations, with a concentration near 0%. This indicates a high degree of forecast accuracy over the short planning horizon.
In medium-term planning, the distribution is broader and the center of gravity is further from 0%, indicating increasing uncertainty.
Long-term planning shows the broadest distribution as well as significant positive and negative deviations. The histogram makes it clear that forecast uncertainty increases significantly as the planning horizon lengthens.
-
Terms
Class (Bin): An interval into which measured values are grouped for frequency counting.
Class width: The width of an interval (e.g., 0.5 Pa·s).
Absolute frequency: The number of values in a class.
Relative frequency: The proportion of values in a class (absolute frequency / n).
Density (optional): Relative frequency relative to the class width (for comparison when class widths differ).
Skewness / MultipEAK: Shape characteristics of the distribution (asymmetric or multiple peaks).
-
Formulas
Mean
\( \bar{\mathrm{x}}=\frac{1}{\mathrm{n}}\sum_{i=1}^{\mathrm{n}}\mathrm{x}_i \)
Standard deviation
\( \mathrm{s}=\sqrt{\frac{1}{\mathrm{n}-1}\sum_{i=1}^{\mathrm{n}}(\mathrm{x}_i-\bar{\mathrm{x}})^2} \)
Notation:
x̄ = sample mean
s = sample standard deviation
n = sample size
xi = i-th measurement
-
Keywords
