Zweck des Tools
Vorgehensweise
Einstellmöglichkeiten
Interpretationshilfe
Darstellungsformen
Voraussetzungen
Werkzeuge
Beispiele
Begriffe
Formeln
F-Test
-
Zweck des Tools
Der F-Test dient dazu, zu prüfen, ob sich die Streuungen bzw. Varianzen zweier Gruppen statistisch signifikant unterscheiden. Er wird eingesetzt, um zu beurteilen, ob eine beobachtete Differenz der Variabilität über zufällige Schwankungen hinausgeht.
Die Entscheidung erfolgt über den Vergleich des p-Wertes mit dem festgelegten Signifikanzniveau (in der Regel α = 0,05):
- p ≤ α → H₁ annehmen (H₀ verwerfen)
- p > α → H₀ beibehalten
-
Beispiel Tomatensoße
In der Produktentwicklung wird eine neue Rezeptur für Tomatensoße getestet. Ziel ist es zu prüfen, ob die Streuung der Viskosität der neuen Rezeptur von der bisherigen Rezeptur abweicht.
Hierzu werden Viskositätsmessungen an Proben der alten Rezeptur und der neuen Rezeptur durchgeführt. Die Messwerte beider Gruppen werden unabhängig voneinander erhoben und jeweils als Stichprobe betrachtet.
Mithilfe des F-Tests (2 Stichproben) soll geprüft werden, ob sich die Varianzen bzw. Standardabweichungen der beiden Gruppen statistisch signifikant unterscheiden.
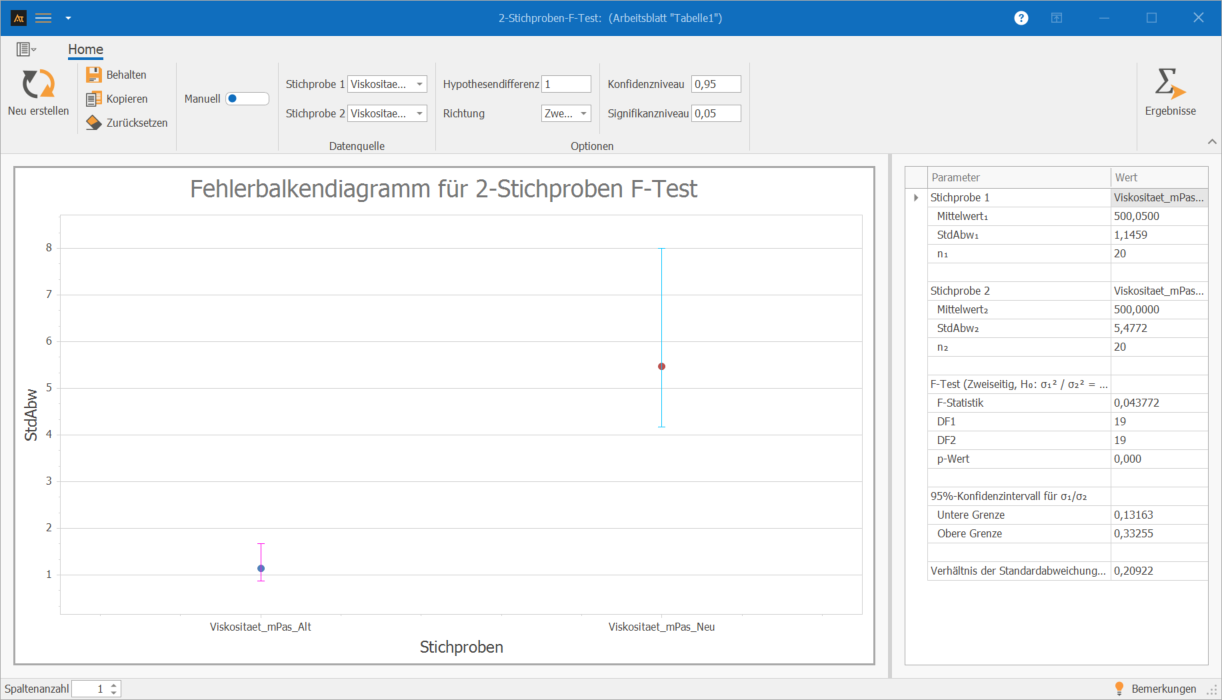
Interpretation der Ergebnisse:
Der ermittelte p-Wert liegt deutlich unter dem Signifikanzniveau von 0,05, sodass die Nullhypothese verworfen wird. Wir entscheiden uns dafür, dass die Streuung der Viskosität der alten und der neuen Rezeptur nicht gleich ist. In diesem Beispiel streut die neue Rezeptur deutlich stärker als die alte.
Erklärungen zur Grafik:
- Die Punkte markieren die Standardabweichungen der Viskosität für die alte und neue Rezeptur.
- Die Fehlerbalken stellen das 95-%-Konfidenzintervall für die jeweilige Standardabweichung dar.
- Die nicht überlappenden Konfidenzintervalle zeigen ebenfalls, dass ein Unterschied in der Standardabweichung vorhanden ist. Der F-Test bestätigt, dass dieser Unterschied statistisch signifikant ist.
-
Vorgehensweise
(Wie ist diese Grafik entstanden?)
Vorarbeit
- Eine geeignete Messgröße auswählen, deren Streuung verglichen werden soll (z. B. Viskosität).
- Zwei Gruppen festlegen, deren Varianzen bzw. Standardabweichungen verglichen werden sollen (z. B. Viskosität alte vs. neue Rezeptur).
- Signifikanzniveau festlegen (in der Regel α = 0,05).
- Prüfen, ob die Daten keine Hinweise auf starke Abweichungen von der Normalverteilung zeigen.
 Nutzung in AlphadiTab
Nutzung in AlphadiTab
- In der Analyze-Phase das Tool 2-Stichproben-F auswählen.
- Bei Stichprobe 1 „Viskositaet_mPas_Alt“ angeben.
- Bei Stichprobe 2 „Viskositaet_mPas_Neu“ angeben.
- Die Analyze durch „Neu erstellen“ durchführen.
Interpretation
- Prüfen, ob der p-Wert kleiner oder gleich dem Signifikanzniveau ist.
p ≤ α → statistisch signifikanter Unterschied der Varianzen bzw. Streuungen.
p > α → kein statistisch signifikanter Unterschied der Varianzen bzw. Streuungen.
Wichtig: Die Interpretation bezieht sich ausschließlich auf die Streuung, nicht auf den Mittelwert.
-
Einstellmöglichkeiten
Daten
Manuelle Eingabe:

Der Vergleich erfolgt auf Basis von manuell eingegebenen Standardabweichungen und Stichprobengrößen zweier Stichproben.
Nicht-manuelle Eingabe:

Der Vergleich erfolgt auf Basis der ausgewählten Datenspalten.
Richtung (Hypothesenart)
Mit der Richtung legen Sie fest, welche Art von Unterschied zwischen den beiden Stichproben geprüft werden soll.
Zweiseitig
Nullhypothese
H₀: σ₁² / σ₂² = 1
Alternativhypothese
H₁: σ₁² / σ₂² ≠ 1
Wählen Sie zweiseitig, wenn Sie prüfen möchten, ob sich die Varianzen der beiden Stichproben unterscheiden, ohne eine bestimmte Richtung vorzugeben.
- Es wird getestet, ob die Streuung der ersten Stichprobe größer oder kleiner als die der zweiten ist.
- Diese Einstellung ist sinnvoll, wenn keine konkrete Erwartung über die Richtung des Unterschieds besteht.
Beispiel:
Unterscheiden sich die Streuungen der Reaktionszeiten von Gruppe A und Gruppe B?
Größer
Nullhypothese
H₀: σ₁² / σ₂² ≤ 1
Alternativhypothese
H₁: σ₁² / σ₂² > 1
Wählen Sie größer, wenn Sie prüfen möchten, ob die Varianz der ersten Stichprobe größer ist als die der zweiten Stichprobe.
- Es wird nur getestet, ob Stichprobe 1 signifikant stärker streut als Stichprobe 2.
- Unterschiede in die andere Richtung werden nicht berücksichtigt.
Beispiel:
Ist die Streuung der Lieferzeit vor einer Maßnahme größer als danach?
Kleiner
Nullhypothese
H₀: σ₁² / σ₂² ≥ 1
Alternativhypothese
H₁: σ₁² / σ₂² < 1
Wählen Sie kleiner, wenn Sie prüfen möchten, ob die Varianz der ersten Stichprobe kleiner ist als die der zweiten Stichprobe.
- Es wird nur getestet, ob Stichprobe 1 signifikant geringere Streuung als Stichprobe 2 hat.
- Unterschiede in die entgegengesetzte Richtung werden nicht berücksichtigt.
Beispiel:
Ist die Streuung der Viskosität der alten Rezeptur kleiner als die der neuen?
-
Voraussetzungen
Zwei Gruppen
Es müssen genau zwei Gruppen vorliegen, deren Varianzen bzw. Standardabweichungen miteinander verglichen werden sollen (z. B. alte vs. neue Rezeptur).
Warum ist das wichtig?
Der F-Test ist ein Verfahren zum Vergleich von zwei Varianzen.
Unabhängige Stichproben
Die Messwerte der beiden Gruppen dürfen sich nicht gegenseitig beeinflussen (keine Paarung derselben Teile).
Warum ist das wichtig?
Der Test setzt voraus, dass die Gruppen unabhängig voneinander erhoben wurden.
Stetige Messdaten
Die Messwerte sollten stetig und hinreichend fein abgestuft sein.
Warum ist das wichtig?
Der F-Test vergleicht Varianzen numerischer Messdaten.
Normalverteilte Daten
Die wiederholten Messwerte sollten keine Hinweise auf eine relevante Abweichung von der Normalverteilung zeigen.
Warum ist das wichtig?
- Der F-Test basiert stark auf der Annahme normalverteilter Daten. Bei deutlichen Abweichungen können die Testergebnisse unzuverlässig sein.
- Bei stark schiefen Verteilungen oder ausgeprägten Ausreißern sollte daher eher ein robuster Varianztest wie der Levene-Test eingesetzt werden.
-
Werkzeuge
(Wann sind andere besser geeignet?)
Wenn mehr als zwei Gruppen gleichzeitig hinsichtlich ihrer Varianzen verglichen werden sollen, dann sind robuste Verfahren wie der Levene-Test über mehrere Gruppen besser geeignet.
Wenn die Daten stark schief verteilt sind oder ausgeprägte Ausreißer enthalten, dann sollte ein robusteres Verfahren verwendet werden.
Wenn Mittelwerte verglichen werden sollen, dann sind ein t-Test oder eine ANOVA besser geeignet.
Wenn nicht Varianzen, sondern Anteile verglichen werden sollen, dann ist ein Anteils-Test das passende Werkzeug.
-
Beispiele
Produktion
Abfüllmenge Tomatensoße – Maschine A vs. Maschine B
In der Produktion werden zwei Abfüllmaschinen eingesetzt. Es soll untersucht werden, ob sich die Streuung der Abfüllmenge zwischen Maschine A und Maschine B unterscheidet.
Für beide Maschinen liegen die Messdaten in zusammengefasster Form vor.
- Maschine A: n = 25, Mittelwert = 500,2 ml, Standardabweichung = 1,1 ml
- Maschine B: n = 25, Mittelwert = 498,9 ml, Standardabweichung = 1,0 ml
Der Vergleich der Streuungen erfolgt mithilfe eines F-Tests (2 Stichproben).
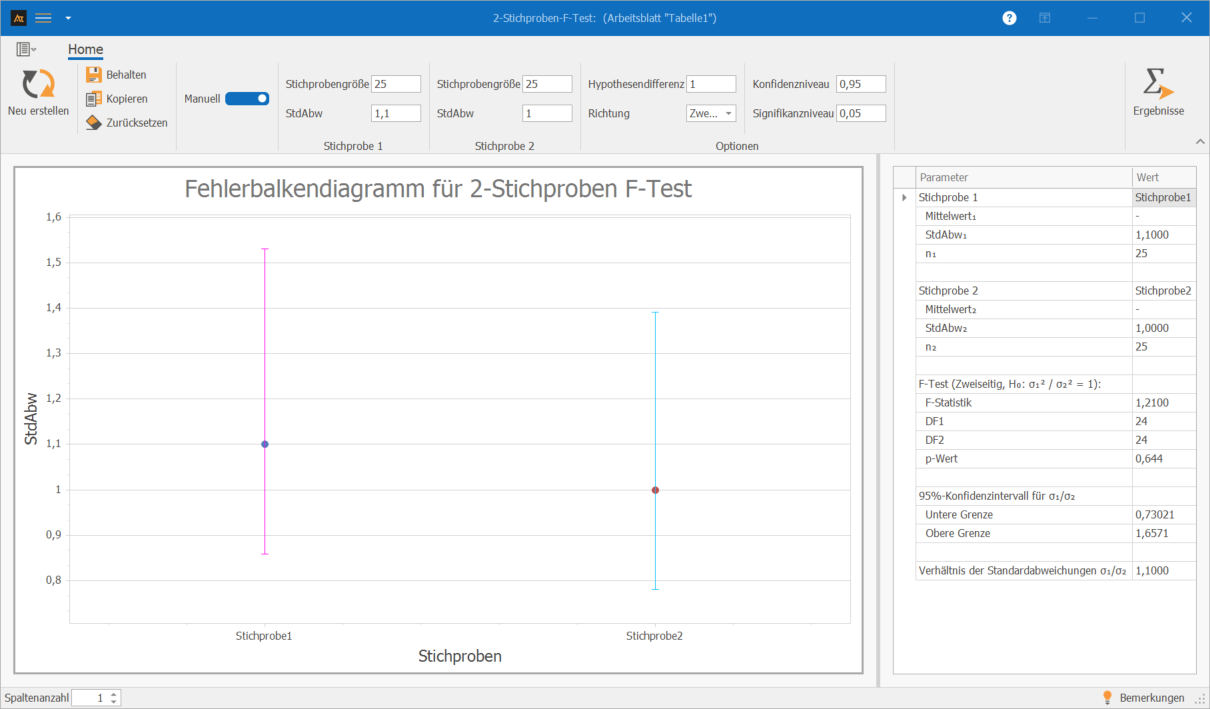
Interpretation:
Der F-Test zeigt keinen statistisch signifikanten Unterschied der Streuung der Abfüllmenge zwischen den beiden Maschinen. Der p-Wert liegt mit 0,644 über 0,05, sodass die Nullhypothese beibehalten wird.
IT-Helpdesks
Reaktionszeit
Im IT-Service-Desk werden Tickets an mehreren Standorten bearbeitet. Die Reaktionszeiten werden regelmäßig ausgewertet, um Unterschiede in der Prozessstabilität zu erkennen.
Im Beispiel der IT-Tickets liegen Daten von drei Standorten vor. Der F-Test (2 Stichproben) ist grundsätzlich nur für den Vergleich von zwei Gruppen geeignet.
Sind mehr als zwei Standorte vorhanden, gibt es zwei mögliche Vorgehensweisen:
Paarweise Vergleiche mit dem F-Test
Jeder Standort kann paarweise mit den anderen Standorten verglichen werden (z. B. Standort A vs. B, A vs. C, B vs. C). Dabei wird jeweils geprüft, ob sich die Streuungen der Reaktionszeiten zwischen zwei Standorten statistisch signifikant unterscheiden.
Alternative: Levene-Test über mehrere Gruppen
Sollen alle Standorte gleichzeitig betrachtet werden, ist ein robuster Varianzvergleich über mehrere Gruppen in der Regel das geeignetere Werkzeug.
Hinweis zur Interpretation
Bei mehreren paarweisen F-Tests steigt das Risiko von Zufallstreffern. Für eine Gesamtbetrachtung der Standorte ist daher ein Verfahren für mehrere Gruppen in der Regel vorzuziehen.
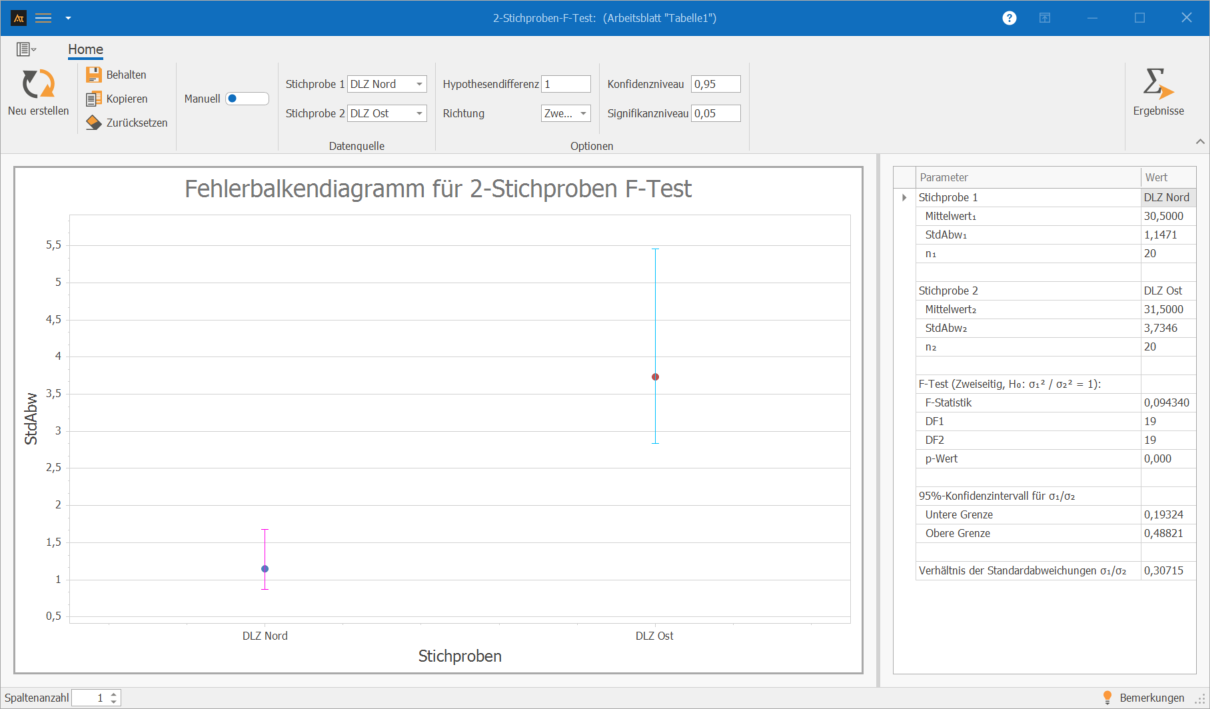
Interpretation:
Der F-Test zeigt einen statistisch signifikanten Unterschied zwischen den Streuungen der Durchlaufzeiten der Standorte DLZ Nord und DLZ Ost. Der p-Wert liegt bei 0,000 und damit unter dem Signifikanzniveau von 0,05.
Aus statistischer Sicht streuen die Durchlaufzeiten am Standort Ost deutlich stärker als am Standort Nord.
Vertrieb
Durchlaufzeit nach Team
Im Vertrieb werden Kundenangebote von zwei Teams bearbeitet. Es soll untersucht werden, ob sich die Streuung der Durchlaufzeit zwischen Team A und Team B unterscheidet.
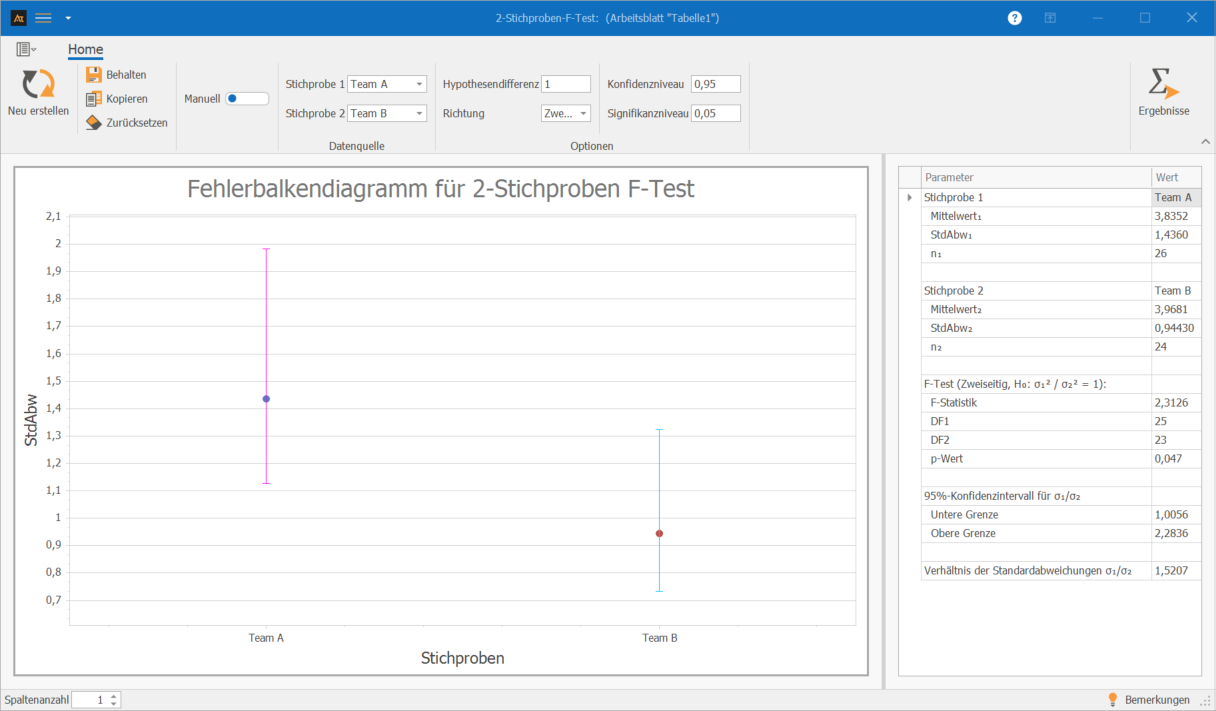
Interpretation:
Der F-Test zeigt einen statistisch signifikanten Unterschied in der Streuung der Durchlaufzeit zwischen den beiden Teams. Der p-Wert liegt mit 0,047 knapp unter 0,05, sodass die Nullhypothese verworfen wird.
Team A weist in diesem Beispiel die höhere Streuung der Durchlaufzeit auf und arbeitet damit weniger gleichmäßig als Team B.
Logistik
Lieferzeit nach Logistikzentrum
In der Logistikabteilung werden Kundenaufträge kommissioniert und versendet. Zur Effizienzsteigerung wurden neue Stapler eingeführt.
Es soll untersucht werden, ob sich die Streuung der Lieferzeit (in Stunden) nach der Einführung der neuen Stapler verringert hat.
Die Analyse erfolgt mithilfe eines F-Tests für zwei Stichproben als einseitiger Test, hier wurde „größer“ ausgewählt.
H₀: σ_Vorher² / σ_Nachher² ≤ 1
H₁: σ_Vorher² / σ_Nachher² > 1
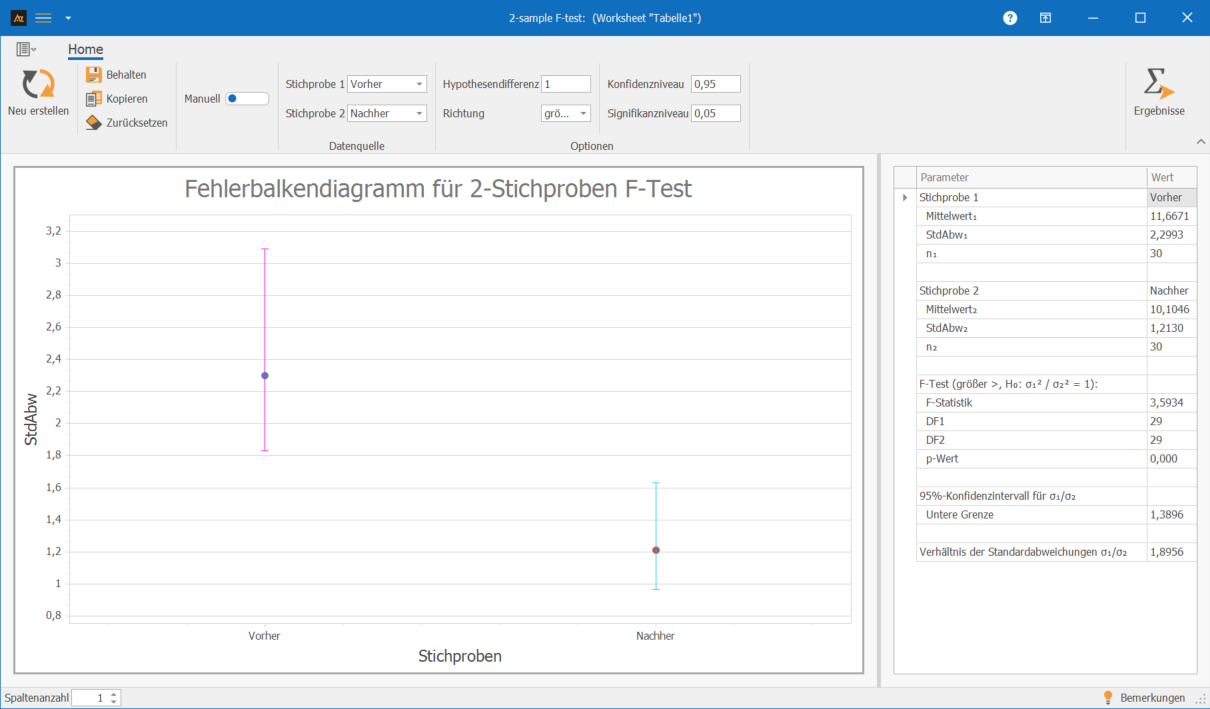
Interpretation:
Der einseitige F-Test zeigt einen statistisch signifikanten Unterschied zwischen den Streuungen der Lieferzeiten vor und nach der Einführung der neuen Stapler (F = 3,5934; p = 0,000).
Da der p-Wert unter dem Signifikanzniveau von 0,05 liegt, wird die Nullhypothese verworfen. Die Lieferzeiten vor der Einführung streuen signifikant stärker als nach der Einführung.
Damit kann geschlossen werden, dass die Einführung der neuen Stapler nicht nur den Mittelwert beeinflussen kann, sondern in diesem Beispiel auch zu einer stabileren Lieferzeit geführt hat.
Einkauf
Lieferantenvergleich
Im Einkauf werden Bauteile von zwei Lieferanten bezogen. Es soll untersucht werden, ob sich die Streuung des Ausschussanteils pro Lieferung zwischen Lieferant A und Lieferant B unterscheidet. Der Ausschussanteil wird je Lieferung in % gemessen.
Hinweis:
Der F-Test setzt annähernd normalverteilte, metrische Daten voraus.
Prozentwerte wie die Ausschussquote können diskret sein, da sie aus Zählwerten entstehen. Bei kleinen Liefermengen entstehen nur wenige mögliche Prozentwerte. In solchen Fällen kann die Normalverteilungsannahme verletzt sein und der F-Test ist möglicherweise nicht geeignet.
Bei größeren Liefermengen mit vielen möglichen Ausprägungen ist der F-Test in der Praxis eher vertretbar; bei Zweifeln sollte ein robusteres Verfahren verwendet werden.
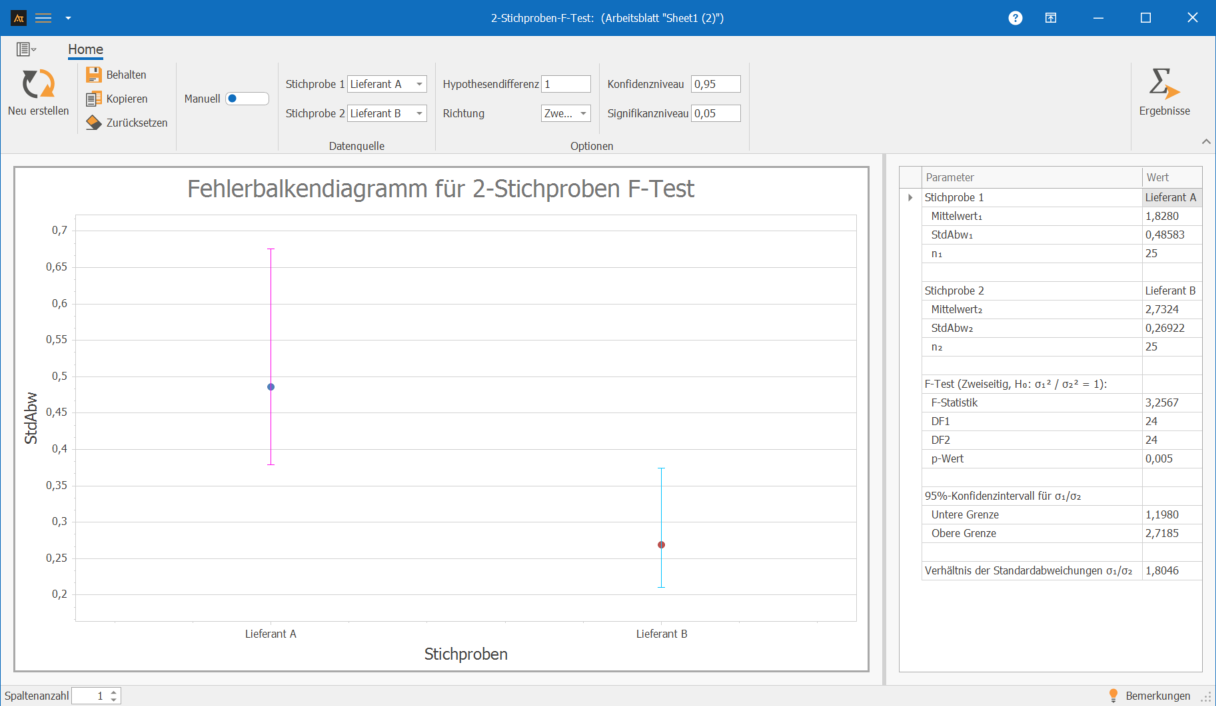
Interpretation:
Der F-Test zeigt einen statistisch signifikanten Unterschied in der Streuung des Ausschussanteils zwischen den Lieferanten (p = 0,005). Die Nullhypothese wird verworfen.
Lieferant A weist in diesem Beispiel die höhere Streuung auf. Lieferant B arbeitet hinsichtlich der Ausschussquote gleichmäßiger.
Planung
Prognoseabweichung
In der Produktionsplanung werden Bedarfsprognosen für unterschiedliche Planungszeiträume erstellt. Zur Bewertung der Prognosegüte wird die Prognoseabweichung berechnet.
Es soll untersucht werden, ob sich die Streuung der Prognoseabweichung zwischen kurzfristigem und langfristigem Planungszeitraum unterscheidet.
Kurzfristiger Planungshorizont:
n = 30, Standardabweichung = 1,5 %
Langfristiger Planungshorizont
n = 30, Standardabweichung = 3,8 %
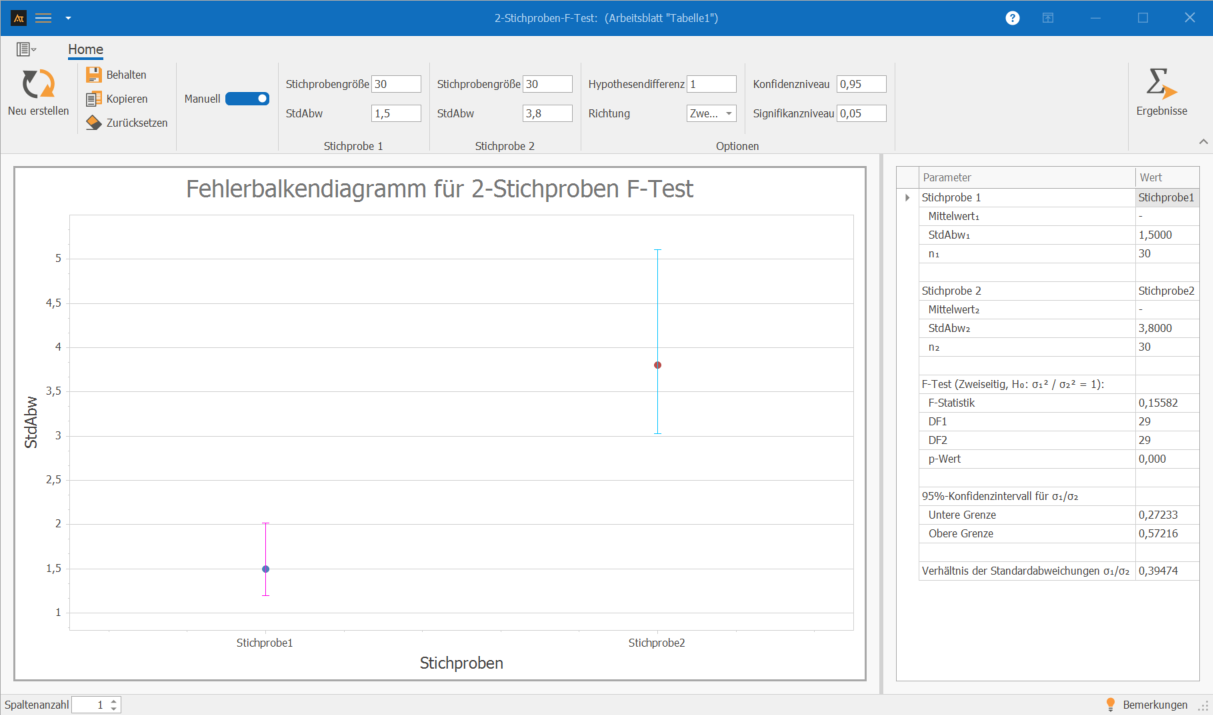
Interpretation:
Der F-Test für zwei unabhängige Stichproben zeigt, dass sich die Streuungen der kurzfristigen und langfristigen Planungszeiträume statistisch signifikant unterscheiden.
Da der p-Wert mit 0,000 unter dem Signifikanzniveau von 0,05 liegt, wird die Nullhypothese verworfen.
Es gibt somit einen statistischen Hinweis darauf, dass die Prognoseabweichungen im langfristigen Planungshorizont deutlich stärker streuen als im kurzfristigen.
-
Begriffe
Stetige Daten: Daten, die mit einem Messmittel erfasst werden und sowohl Einheiten als auch Nachkommastellen besitzen können.
Normalverteilte Daten: Daten, die sich gut durch eine Normalverteilung beschreiben lassen. Dies kann z. B. über einen Test auf Normalverteilung überprüft werden.
x̄ = Mittelwert der Stichprobe: Durchschnittswert der erhobenen Messdaten. Er kann in der Ausgabe angezeigt werden, ist aber nicht die eigentliche Prüfgröße des F-Tests.
s = Standardabweichung der Stichprobe: Maß für die Streuung der Daten um den Mittelwert.
n = Stichprobengröße: Anzahl der Beobachtungen innerhalb einer Stichprobe.
α = Signifikanzniveau: Vorgegebene Irrtumswahrscheinlichkeit, mit der die Nullhypothese fälschlicherweise verworfen wird.
p-Wert: Ergebnis des Hypothesentests, mit dem eine Entscheidung zwischen den beiden Hypothesen getroffen wird.
F-Wert bzw. F-Statistik: Prüfgröße des F-Tests. Sie ergibt sich aus dem Verhältnis der beiden Stichprobenvarianzen.
DF1 / DF2 = Freiheitsgrade: Werte, die sich aus den Stichprobengrößen beider Gruppen ergeben und die Form der F-Verteilung bestimmen.
σ₁² / σ₂² = Varianzverhältnis: Referenzgröße des Tests. Unter der Nullhypothese ist dieses Verhältnis gleich 1.
Konfidenzniveau: Wahrscheinlichkeit, mit der das berechnete Konfidenzintervall den wahren Parameterwert überdeckt (z. B. 95 %).
Konfidenzintervall: Wertebereich, der mit dem gewählten Konfidenzniveau das wahre Varianzverhältnis enthält.
Nullhypothese: Ausgangshypothese, die von gleichen Varianzen bzw. von einem Varianzverhältnis von 1 ausgeht. Sie wird im Hypothesentest geprüft.
Alternativhypothese: Gegenhypothese zur Nullhypothese. Sie beschreibt die inhaltliche Fragestellung, z. B. ob sich Varianzen signifikant unterscheiden.
Richtung des Tests: Gibt an, ob ein Unterschied ohne Vorgabe der Richtung (zweiseitig) oder eine konkrete Richtung (größer/kleiner) geprüft wird.
Zweiseitig: Es wird geprüft, ob sich die Varianzen unterscheiden, unabhängig davon, in welche Richtung.
Größer: Es wird geprüft, ob die Varianz der ersten Stichprobe größer ist als die der zweiten Stichprobe.
Kleiner: Es wird geprüft, ob die Varianz der ersten Stichprobe kleiner ist als die der zweiten Stichprobe.
Stetige Daten: Daten, die mit einem Messmittel erfasst werden und sowohl Einheiten als auch Nachkommastellen besitzen können.
Normalverteilte Daten: Daten, die sich gut durch eine Normalverteilung beschreiben lassen. Dies kann z. B. über einen Test auf Normalverteilung überprüft werden.
x̄ = Mittelwert der Stichprobe: Durchschnittswert der erhobenen Messdaten. Er kann in der Ausgabe angezeigt werden, ist aber nicht die eigentliche Prüfgröße des F-Tests.
s = Standardabweichung der Stichprobe: Maß für die Streuung der Daten um den Mittelwert.
n = Stichprobengröße: Anzahl der Beobachtungen innerhalb einer Stichprobe.
α = Signifikanzniveau: Vorgegebene Irrtumswahrscheinlichkeit, mit der die Nullhypothese fälschlicherweise verworfen wird.
p-Wert: Ergebnis des Hypothesentests, mit dem eine Entscheidung zwischen den beiden Hypothesen getroffen wird.
F-Wert bzw. F-Statistik: Prüfgröße des F-Tests. Sie ergibt sich aus dem Verhältnis der beiden Stichprobenvarianzen.
DF1 / DF2 = Freiheitsgrade: Werte, die sich aus den Stichprobengrößen beider Gruppen ergeben und die Form der F-Verteilung bestimmen.
σ₁² / σ₂² = Varianzverhältnis: Referenzgröße des Tests. Unter der Nullhypothese ist dieses Verhältnis gleich 1.
Konfidenzniveau: Wahrscheinlichkeit, mit der das berechnete Konfidenzintervall den wahren Parameterwert überdeckt (z. B. 95 %).
Konfidenzintervall: Wertebereich, der mit dem gewählten Konfidenzniveau das wahre Varianzverhältnis enthält.
Nullhypothese: Ausgangshypothese, die von gleichen Varianzen bzw. von einem Varianzverhältnis von 1 ausgeht. Sie wird im Hypothesentest geprüft.
Alternativhypothese: Gegenhypothese zur Nullhypothese. Sie beschreibt die inhaltliche Fragestellung, z. B. ob sich Varianzen signifikant unterscheiden.
Richtung des Tests: Gibt an, ob ein Unterschied ohne Vorgabe der Richtung (zweiseitig) oder eine konkrete Richtung (größer/kleiner) geprüft wird.
Zweiseitig: Es wird geprüft, ob sich die Varianzen unterscheiden, unabhängig davon, in welche Richtung.
Größer: Es wird geprüft, ob die Varianz der ersten Stichprobe größer ist als die der zweiten Stichprobe.
Kleiner: Es wird geprüft, ob die Varianz der ersten Stichprobe kleiner ist als die der zweiten Stichprobe.
-
Formeln
F-Teststatistik
\( \mathrm{F}=\frac{\frac{\mathrm{s}_1^2}{\mathrm{s}_2^2}}{\mathrm{k}^2} \)
Freiheitsgrade
\( \mathrm{df}_1=\mathrm{n}_1-1 \)
\( \mathrm{df}_2=\mathrm{n}_2-1 \)
Konfidenzintervall (untere Grenze)
\( \mathrm{untere\ Grenze}=\sqrt{\frac{\mathrm{s}_1^2}{\mathrm{s}_2^2}\cdot \mathrm{F}_{\mathrm{unten}}} \)
Konfidenzintervall (obere Grenze)
\( \mathrm{obere\ Grenze}=\sqrt{\frac{\mathrm{s}_1^2}{\mathrm{s}_2^2}\cdot \mathrm{F}_{\mathrm{oben}}} \)
Verhältnis der Standardabweichungen
\( \frac{\mathrm{s}_1}{\mathrm{s}_2}=\sqrt{\frac{\mathrm{s}_1^2}{\mathrm{s}_2^2}} \)
Hinweis:
Für die Berechnung der Stichproben-Standardabweichungen sowie der Verteilungs- und Quantilswerte der F- und Chi-Quadrat-Verteilung wurde auf NMath zurückgegriffen.
-
Schlagwörter
