Zweck des Tools
Vorgehensweise
Einstellmöglichkeiten
Interpretationshilfe
Darstellungsformen
Voraussetzungen
Werkzeuge
Beispiele
Begriffe
Formeln
ANOVA
-
Zweck des Tools
Die ANOVA dient dazu, zu prüfen, ob sich die Mittelwerte von zwei oder mehr Gruppen statistisch signifikant unterscheiden.
Sie wird eingesetzt, um zu beurteilen, ob beobachtete Unterschiede zwischen Gruppen über zufällige Schwankungen hinausgehen.
Grundsätzlich kann die ANOVA auch bei zwei Gruppen durchgeführt werden. Besonders hilfreich ist sie jedoch, wenn mehrere Gruppen gemeinsam betrachtet werden sollen.
Die Entscheidung erfolgt über den Vergleich des p-Wertes mit dem festgelegten Signifikanzniveau (in der Regel α = 0,05):
p ≤ α → H₁ annehmen (H₀ verwerfen)
p > α → H₀ beibehalten
-
Beispiel: Viskosität von Tomatensoße - mehrere Rezepturen
In der Produktentwicklung werden mehrere Rezepturen für Tomatensoße getestet.
Ziel ist es zu prüfen, ob sich die Viskosität der Rezepturen im Mittel unterscheidet.
Hierzu werden Viskositätsmessungen an Proben der Rezeptur A, Rezeptur B und Rezeptur C durchgeführt.
Die Messwerte der Gruppen werden unabhängig voneinander erhoben und jeweils als Stichprobe betrachtet.
Mithilfe der ANOVA soll geprüft werden, ob mindestens ein Gruppenmittelwert statistisch signifikant von den anderen abweicht oder ob die beobachteten Unterschiede durch zufällige Streuung erklärt werden können.
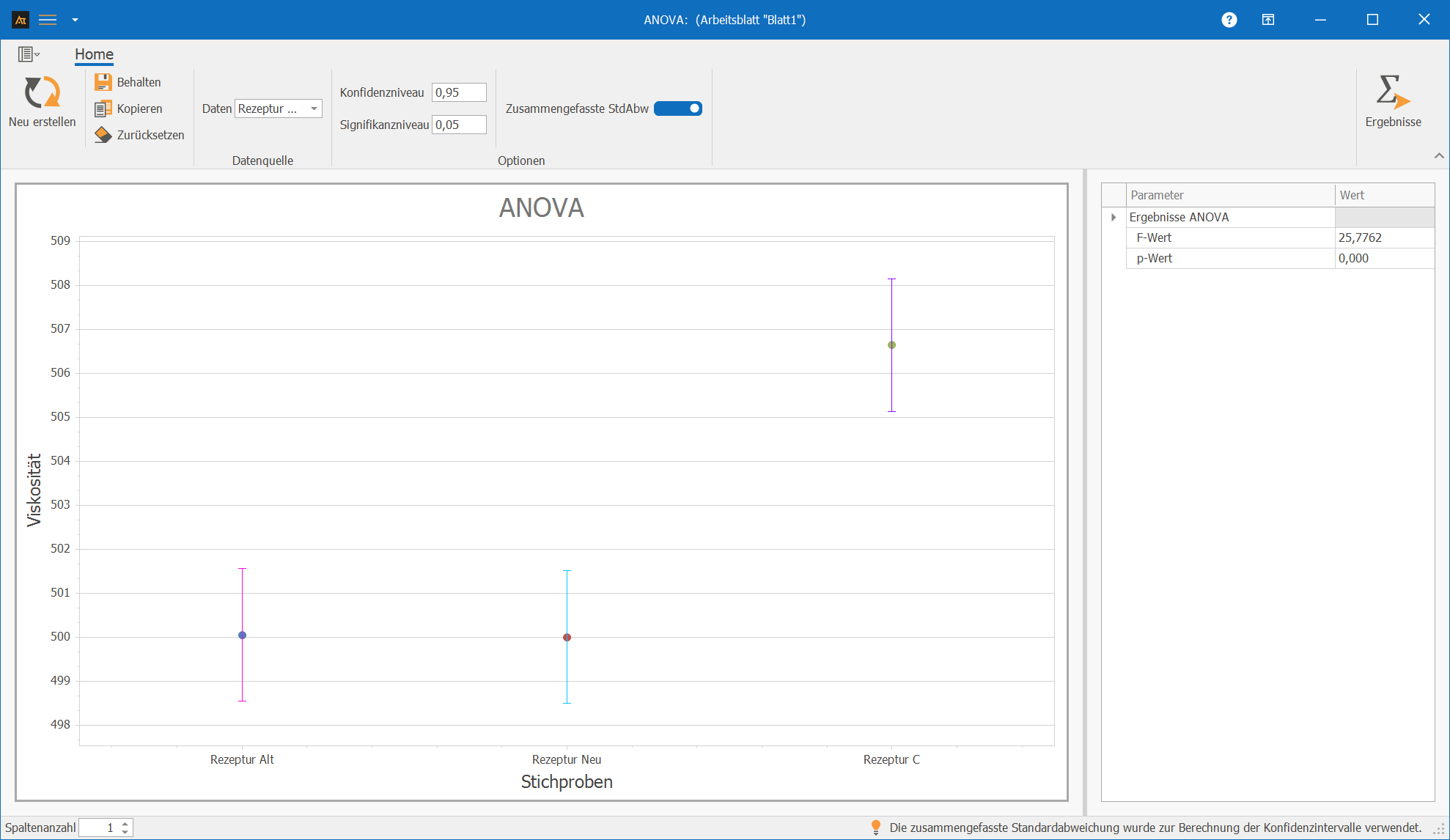
Interpretation der Ergebnisse:
Der ermittelte p-Wert wird mit dem Signifikanzniveau von 0,05 verglichen. Liegt der p-Wert unter oder gleich 0,05, wird die Nullhypothese verworfen. Es wird dann davon ausgegangen, dass nicht alle durchschnittlichen Viskositäten der Rezepturen gleich sind.
Liegt der p-Wert über 0,05, gibt es keinen statistischen Hinweis darauf, dass sich die mittlere Viskosität zwischen den Rezepturen unterscheidet. Da der p-Wert in unserem Beispiel bei 0,000 liegt, wird die Nullhypothese verworfen und die Alternativhypothese angenommen.
Erklärungen zur Grafik:
- Die Punkte markieren die Mittelwerte der Viskosität für die einzelnen Rezepturen.
- Die Fehlerbalken stellen das 95-%-Konfidenzintervall des jeweiligen Mittelwerts dar.
- Überlappungen der Konfidenzintervalle geben einen ersten visuellen Hinweis. Die abschließende Entscheidung erfolgt über den p-Wert und bei Bedarf über paarweise Vergleiche.
-
Vorgehensweise
(Wie ist diese Grafik entstanden?)
Vorarbeit
- Eine stetige Messgröße auswählen (z. B. Viskosität).
- Zwei oder mehr Gruppen festlegen, deren Mittelwerte verglichen werden sollen (z. B. Rezeptur A, B und C).
- Signifikanzniveau festlegen (in der Regel α = 0,05).
- Prüfen, ob die Daten keine Hinweise auf starke Abweichungen von der Normalverteilung zeigen.
- Prüfen, ob die Streuungen der Gruppen ähnlich groß sind.
- Sicherstellen, dass die Messwerte unabhängig voneinander erhoben wurden.
 Nutzung in AlphadiTab
Nutzung in AlphadiTab
- In der Analyze-Phase das Tool ANOVA auswählen.
- Bei Daten alle zu vergleichenden Gruppen auswählen.
- Die Analyze durch „Neu erstellen“ durchführen.
Interpretation
- Prüfen, ob der p-Wert kleiner oder gleich dem Signifikanzniveau ist.
p ≤ α → statistisch signifikanter Unterschied zwischen mindestens zwei Mittelwerten.
p > α → kein statistisch signifikanter Unterschied zwischen den Mittelwerten.
Wichtig: Die ANOVA prüft zunächst alle Gruppen gemeinsam. Welche Gruppen sich unterscheiden, wird über paarweise Vergleiche beurteilt.
-
Voraussetzungen
Zwei oder mehr Gruppen
Es müssen mindestens zwei Gruppen vorliegen, deren Mittelwerte miteinander verglichen werden sollen (z. B. Rezeptur A, Rezeptur B und Rezeptur C).
Warum ist das wichtig?
Die ANOVA ist ein Verfahren zum Vergleich von Mittelwerten zwischen Gruppen. Bei genau zwei Gruppen ist die ANOVA ebenfalls möglich; in der Praxis wird für diesen Spezialfall jedoch häufig der t-Test verwendet.
Unabhängige Stichproben
Die Messwerte der Gruppen dürfen sich nicht gegenseitig beeinflussen (keine Paarung derselben Teile).
Warum ist das wichtig?
- Der Test setzt voraus, dass die Gruppen unabhängig voneinander erhoben wurden.
Stetige Messdaten
Die Messwerte müssen stetig sein.
Warum ist das wichtig?
- Die ANOVA vergleicht Mittelwerte numerischer Messdaten.
Normalverteilte Daten
Die Messwerte sollten keine Hinweise auf eine relevante Abweichung von der Normalverteilung zeigen.
Warum ist das wichtig?
- Die ANOVA basiert auf Annahmen der Normalverteilung. Bei starken Abweichungen können die Testergebnisse unzuverlässig sein.
- Die ANOVA ist gegenüber leichten Abweichungen robust, insbesondere bei ähnlich großen Stichproben. Bei stark schiefen Verteilungen, ausgeprägten Ausreißern oder sehr unterschiedlichen Varianzen sollte ein alternatives Verfahren geprüft werden.
-
Werkzeuge
(Wann sind andere besser geeignet?)
Wenn genau zwei Gruppen miteinander verglichen werden sollen und ausschließlich dieser Vergleich interessiert, kann ein t-Test die einfachere Alternative sein.
Wenn die Daten stark schief verteilt sind oder ausgeprägte Ausreißer enthalten, dann sollte ein nichtparametrisches Verfahren verwendet werden.
Wenn dieselben Teile oder Personen mehrfach gemessen werden, dann ist ein Verfahren für verbundene Messungen geeigneter.
Wenn nicht Mittelwerte, sondern Varianzen verglichen werden sollen, dann sind ein F-Test oder der Levene-Test besser geeignet.
Wenn nicht Mittelwerte, sondern Anteile verglichen werden sollen, dann ist ein Test von Anteilen das passende Werkzeug.
-
Beispiele
IT-Helpdesks
Reaktionszeit des IT-Helpdesks vs. Standort
Im IT-Service-Desk werden Tickets an mehreren Standorten bearbeitet.
Die Reaktionszeiten werden regelmäßig ausgewertet, um Unterschiede in der Servicequalität zu erkennen.
Im Beispiel der IT-Tickets liegen Daten von drei Standorten vor.
Die ANOVA ist für diesen Fall geeignet, weil mehrere Gruppen gleichzeitig verglichen werden. Die ANOVA reduziert das Risiko von Zufallstreffern gegenüber vielen einzelnen t-Tests. Für eine Gesamtbetrachtung der Standorte ist sie daher in der Regel vorzuziehen.
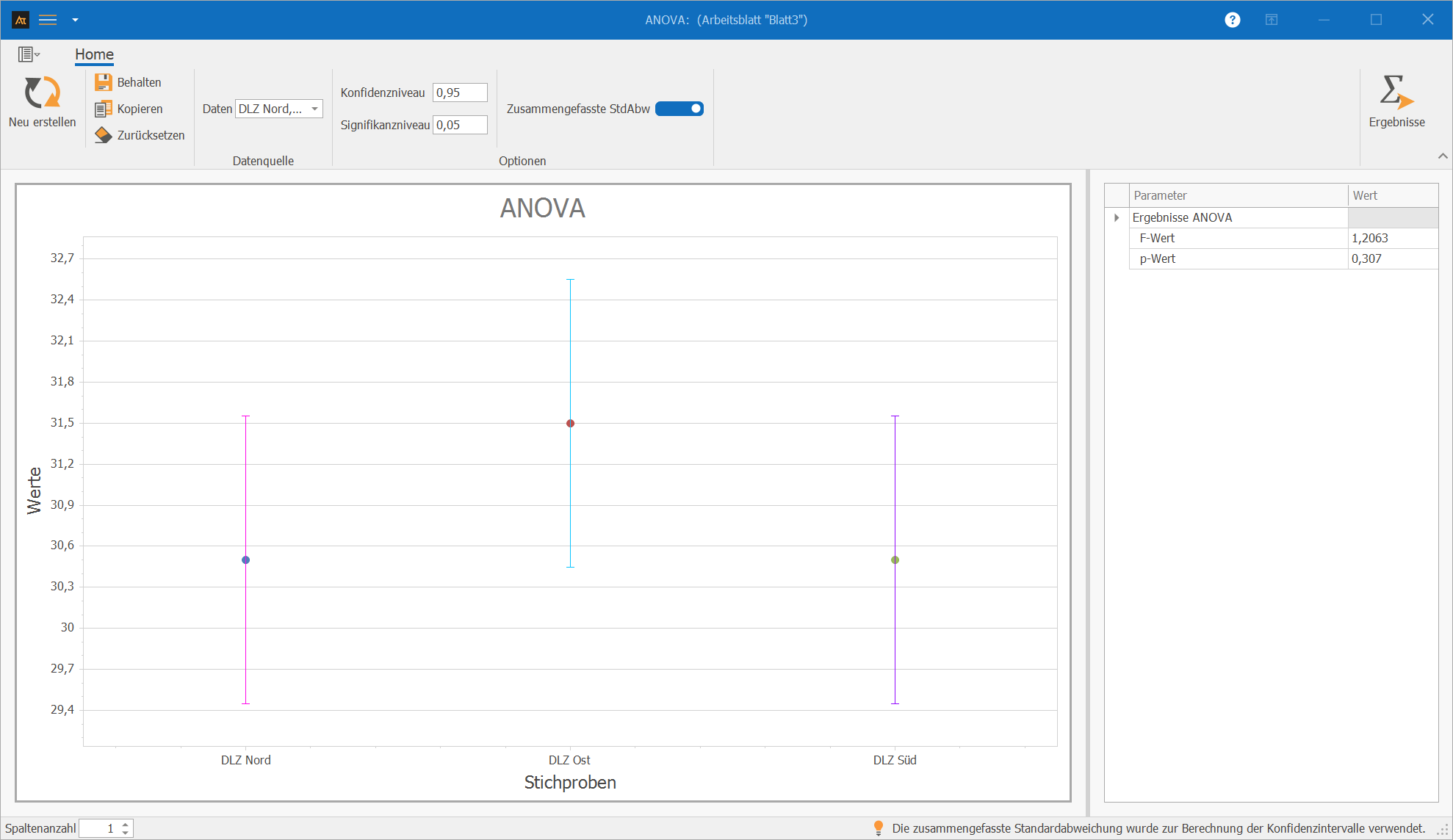
Der p-Wert liegt über dem Signifikanzniveau von 0,05, daher wird die Nullhypothese beibehalten. Aus statistischer Sicht unterscheiden sich die mittleren Durchlaufzeiten der Standorte nicht signifikant.
Vertrieb
Durchlaufzeit nach Region
Im Vertrieb werden Kundenangebote von mehreren Teams bearbeitet.
Es soll untersucht werden, ob sich die mittlere Durchlaufzeit (DLZ) zwischen Team A, Team B und Team C unterscheidet.
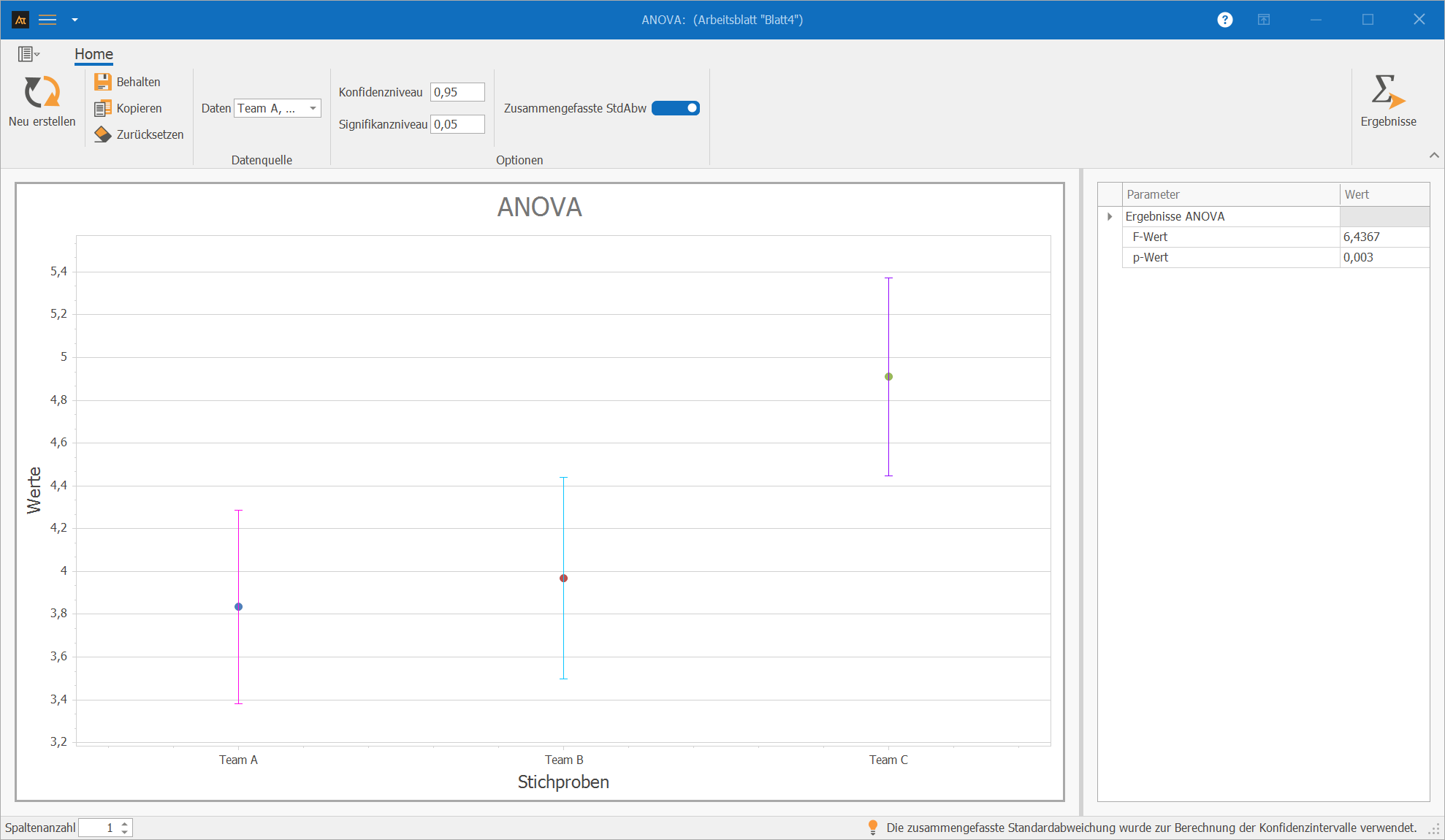
Der p-Wert liegt unter 0,05, sodass die Nullhypothese verworfen wird. Die ANOVA zeigt einen statistisch signifikanten Unterschied in der mittleren Durchlaufzeit zwischen den Teams. Die Teams bearbeiten die Angebote im Mittel nicht gleich schnell.
Logistik
Lieferzeit nach Logistikzentrum
In der Logistikabteilung werden Kundenaufträge kommissioniert und versendet.
Die Lieferzeiten werden in mehreren Logistikzentren miteinander verglichen.
Es soll untersucht werden, ob sich die mittlere Lieferzeit (in Stunden) zwischen den Logistikzentren unterscheidet.
Die Analyse erfolgt mithilfe einer ANOVA mit Logistikzentrum als Faktor.
H₀: μ_Zentrum A = μ_Zentrum B = μ_Zentrum C
H₁: Mindestens ein Mittelwert unterscheidet sich.
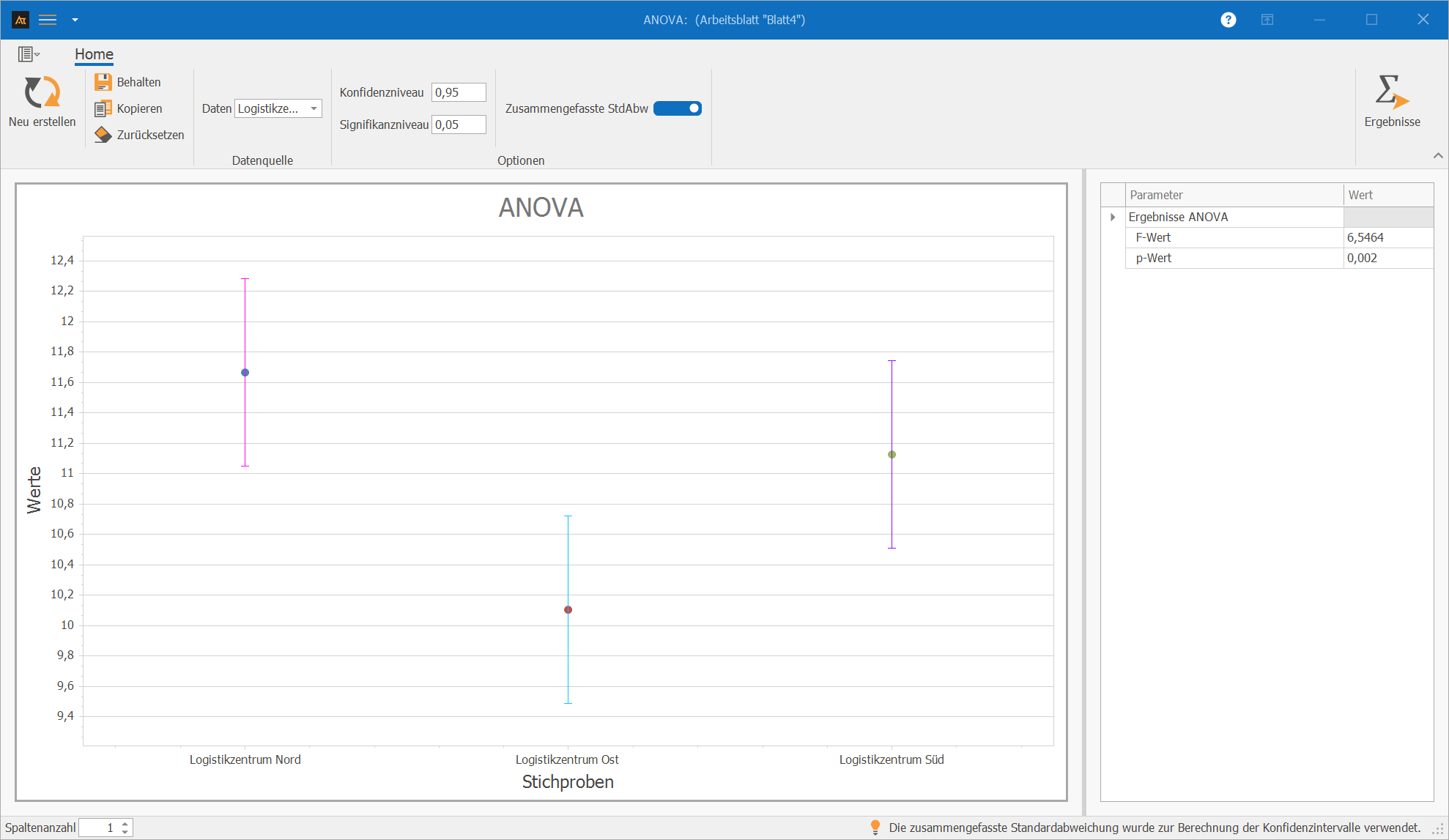
Interpretation:
Die ANOVA zeigt einen statistisch signifikanten Unterschied zwischen den mittleren Lieferzeiten der Logistikzentren (p < 0,05).
Da der p-Wert unter dem Signifikanzniveau von 0,05 liegt, wird die Nullhypothese verworfen.
Mindestens ein Logistikzentrum unterscheidet sich hinsichtlich der durchschnittlichen Lieferzeit.
Einkauf
Lieferantenvergleich
Im Einkauf werden Bauteile von drei Lieferanten bezogen. Es soll untersucht werden, ob sich der mittlere Ausschussanteil pro Lieferung zwischen Lieferant A, Lieferant B und Lieferant C unterscheidet. Der Ausschussanteil wird je Lieferung in % gemessen.
Hinweis:
Die ANOVA setzt annähernd normalverteilte, stetige Daten voraus.
Prozentwerte wie die Ausschussquote können diskret sein, da sie aus Zählwerten entstehen.
Bei kleinen Liefermengen (z. B. 10 Teile pro Lieferung) entstehen nur wenige mögliche Prozentwerte (0 %, 10 %, 20 % …). In solchen Fällen kann die Normalverteilungsannahme verletzt sein und die ANOVA ist möglicherweise nicht geeignet.
Bei größeren Liefermengen mit vielen möglichen Ausprägungen ist die ANOVA in der Praxis in der Regel unproblematisch anwendbar.
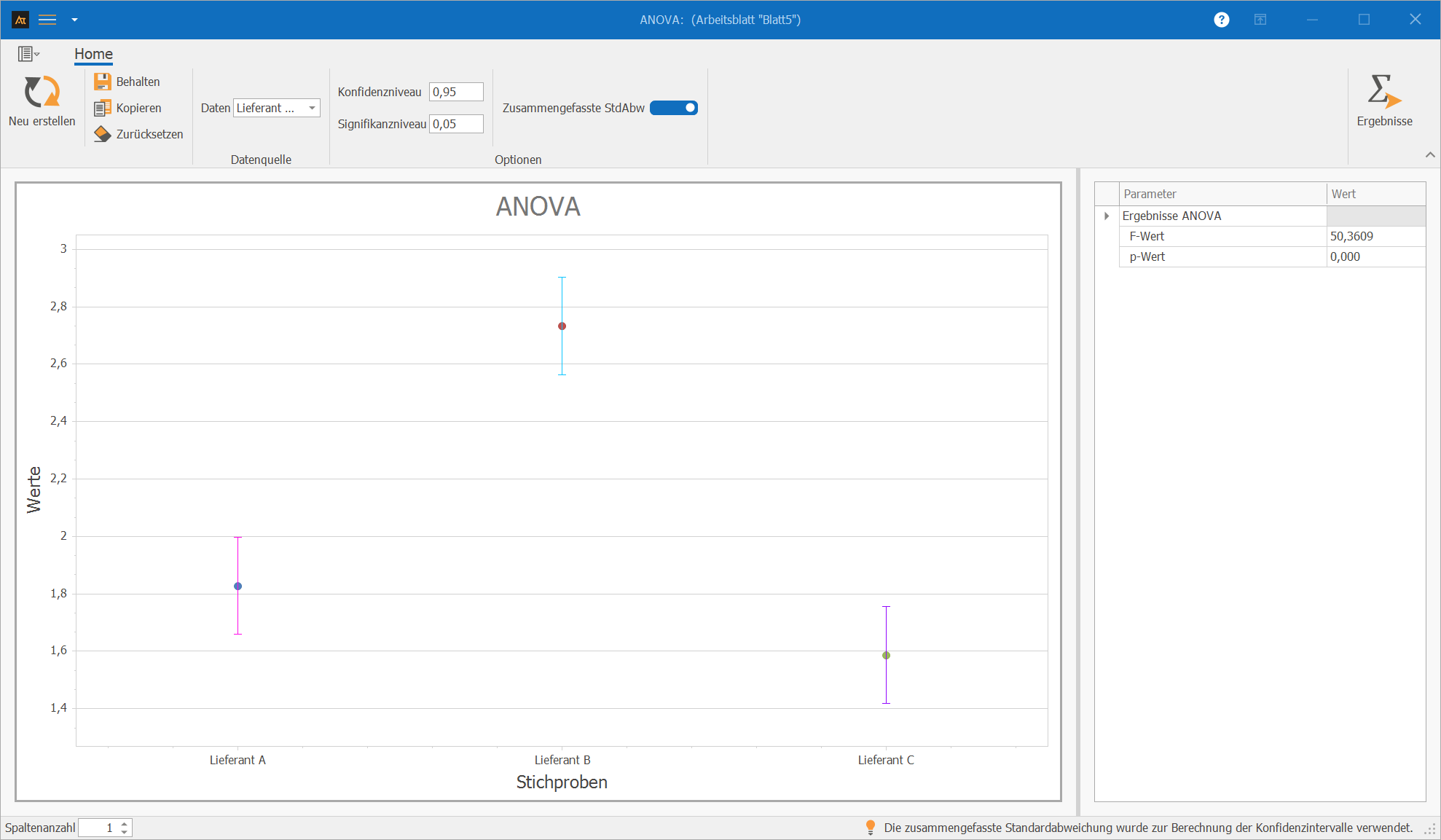
Die ANOVA zeigt einen statistisch signifikanten Unterschied im mittleren Ausschussanteil zwischen den Lieferanten (p < 0,05). Die Nullhypothese wird verworfen. Die Lieferanten unterscheiden sich hinsichtlich der durchschnittlichen Ausschussquote. Paarweise Vergleiche zeigen anschließend, welche Lieferanten sich konkret unterscheiden.
Planung
Prognoseabweichung
In der Produktionsplanung werden Bedarfsprognosen für unterschiedliche Planungszeiträume erstellt.
Zur Bewertung der Prognosegüte wird die Prognoseabweichung berechnet.
Es soll untersucht werden, ob sich die durchschnittliche Prognoseabweichung zwischen kurzfristigem, mittelfristigem und langfristigem Planungszeitraum unterscheidet.
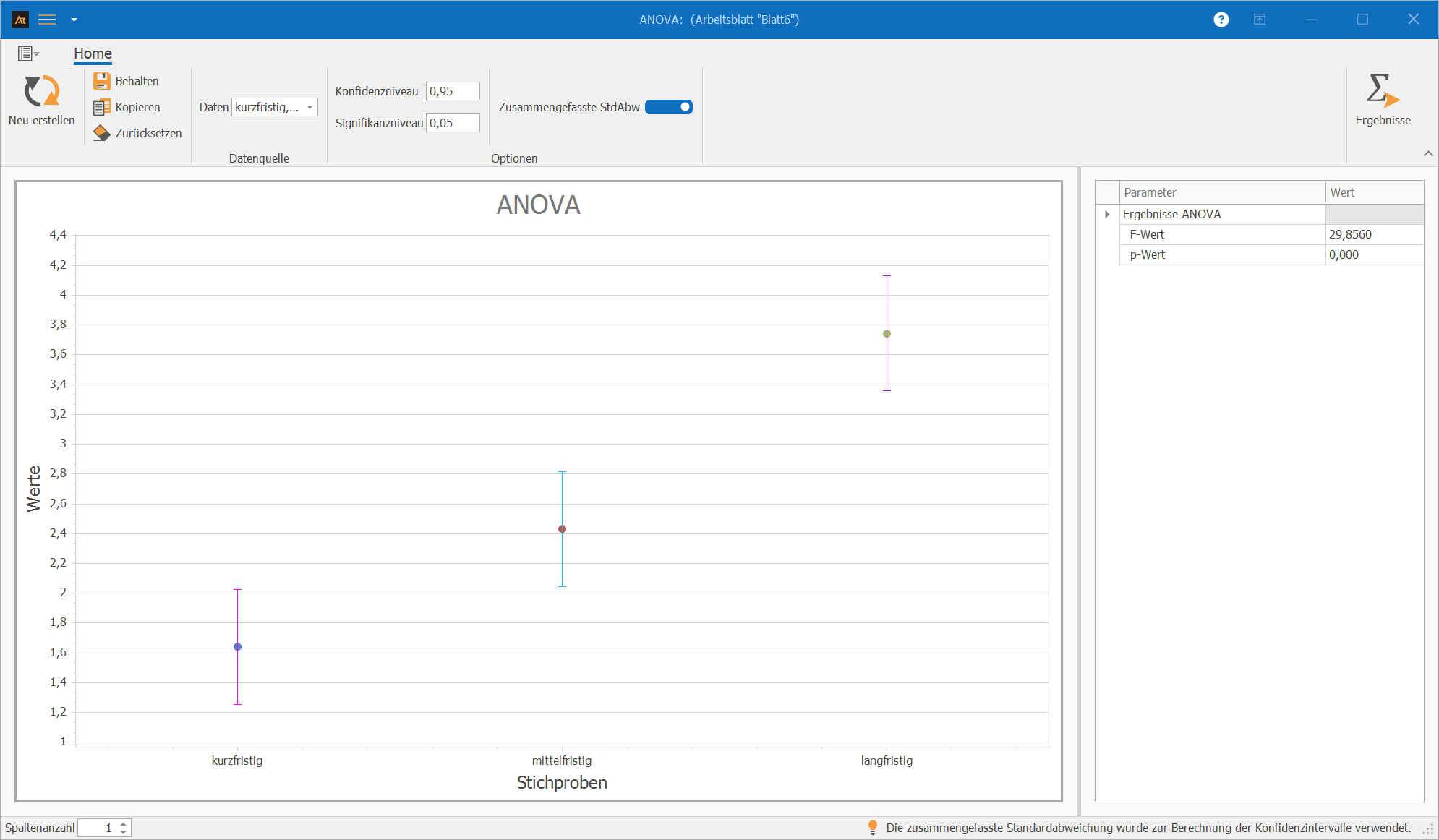
Da der p-Wert unter dem Signifikanzniveau von 0,05 liegt, wird die Nullhypothese verworfen. Es gibt somit einen statistischen Hinweis darauf, dass sich die durchschnittliche Prognoseabweichung zwischen den Planungshorizonten unterscheidet. Im Diagramm erkennt man außerdem, dass die Abweichungen zunehmen, je größer der Planungshorizont wird.
-
Begriffe
Stetige Daten: Daten, die mit einem Messmittel erfasst werden und sowohl Einheiten als auch Nachkommastellen besitzen können.
Normalverteilte Daten: Daten, die sich gut durch eine Normalverteilung beschreiben lassen. Dies kann z. B. über einen Test auf Normalverteilung oder über Residuenplots überprüft werden.
x̄ = Mittelwert der Stichprobe: Durchschnittswert der erhobenen Messdaten.
s = Standardabweichung der Stichprobe: Maß für die Streuung der Daten um den Mittelwert.
n = Stichprobengröße: Anzahl der Beobachtungen innerhalb einer Stichprobe.
α = Signifikanzniveau: Vorgegebene Irrtumswahrscheinlichkeit, mit der die Nullhypothese fälschlicherweise verworfen wird.
p-Wert: Ergebnis des Hypothesentestes, mit dem eine Entscheidung zwischen Nullhypothese und Alternativhypothese getroffen wird.
F-Wert: Prüfgröße der ANOVA. Er beschreibt das Verhältnis der Streuung zwischen den Gruppen zur Streuung innerhalb der Gruppen.
df = Freiheitsgrade: Werte, die sich aus der Anzahl der Gruppen und Beobachtungen ergeben und die Form der F-Verteilung bestimmen.
MS = mittlere Quadratsumme: Quadratsumme geteilt durch die zugehörigen Freiheitsgrade.
Konfidenzniveau: Wahrscheinlichkeit, mit der das berechnete Konfidenzintervall den wahren Parameterwert überdeckt (z. B. 95 %).
Konfidenzintervall: Wertebereich, der mit dem gewählten Konfidenzniveau den wahren Mittelwert oder Mittelwertunterschied enthält.
Nullhypothese: Ausgangshypothese, die bei der ANOVA von gleichen Mittelwerten aller Gruppen ausgeht. Sie wird im Hypothesentest geprüft.
Alternativhypothese: Gegenhypothese zur Nullhypothese. Sie beschreibt, dass mindestens ein Gruppenmittelwert von den anderen abweicht.
Faktor: Kategoriale Einflussgröße, nach der die Messwerte in Gruppen eingeteilt werden.
Stufen/Gruppen: Ausprägungen des Faktors, z. B. Rezeptur A, Rezeptur B und Rezeptur C.
Varianzhomogenität: Annahme, dass die Streuungen der Gruppen ähnlich groß sind.
-
Formeln
